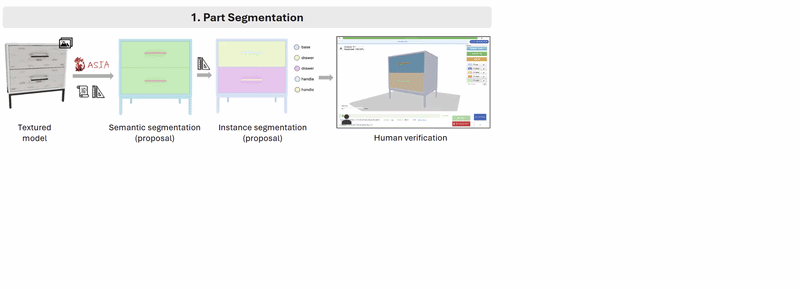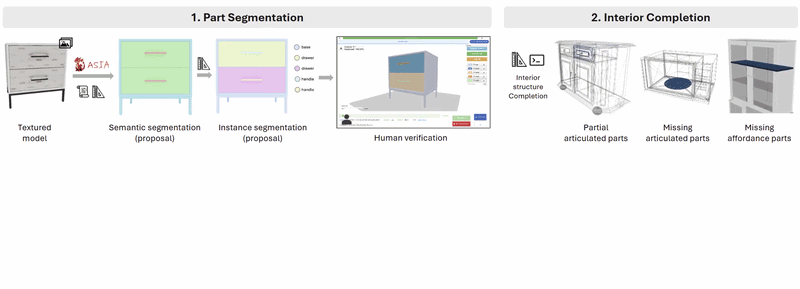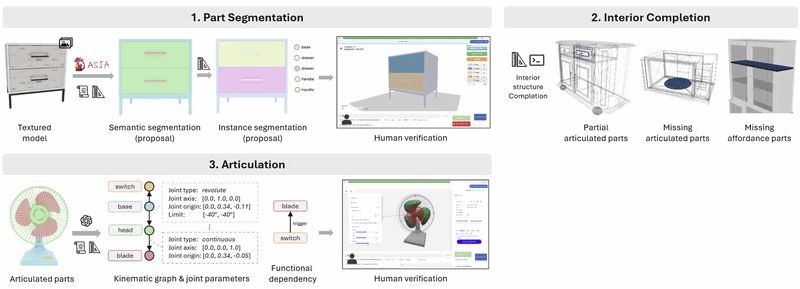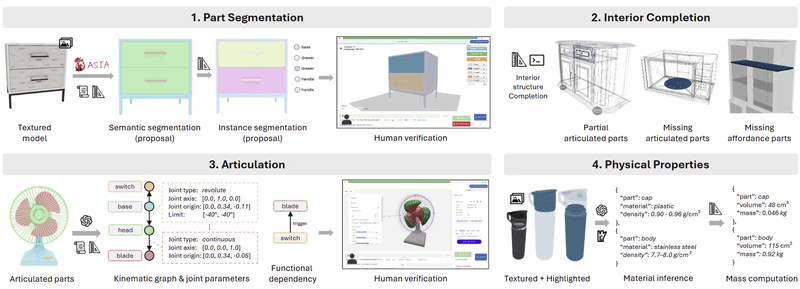
Denys Iliash, Jiayi Liu, Egor Fokin, Qirui Wu, Ali Mahdavi Amiri, Manolis Savva, Angel X Chang
In CVPR (2026)
[
![]() Project Page
]
Project Page
]

Qirui Wu, Yawar Siddiqui, Duncan Frost, Samir Aroudj, Armen Avetisyan, Richard Newcombe, Angel X. Chang, Jakob Engel, and Henry Howard-Jenkins
In CVPR (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
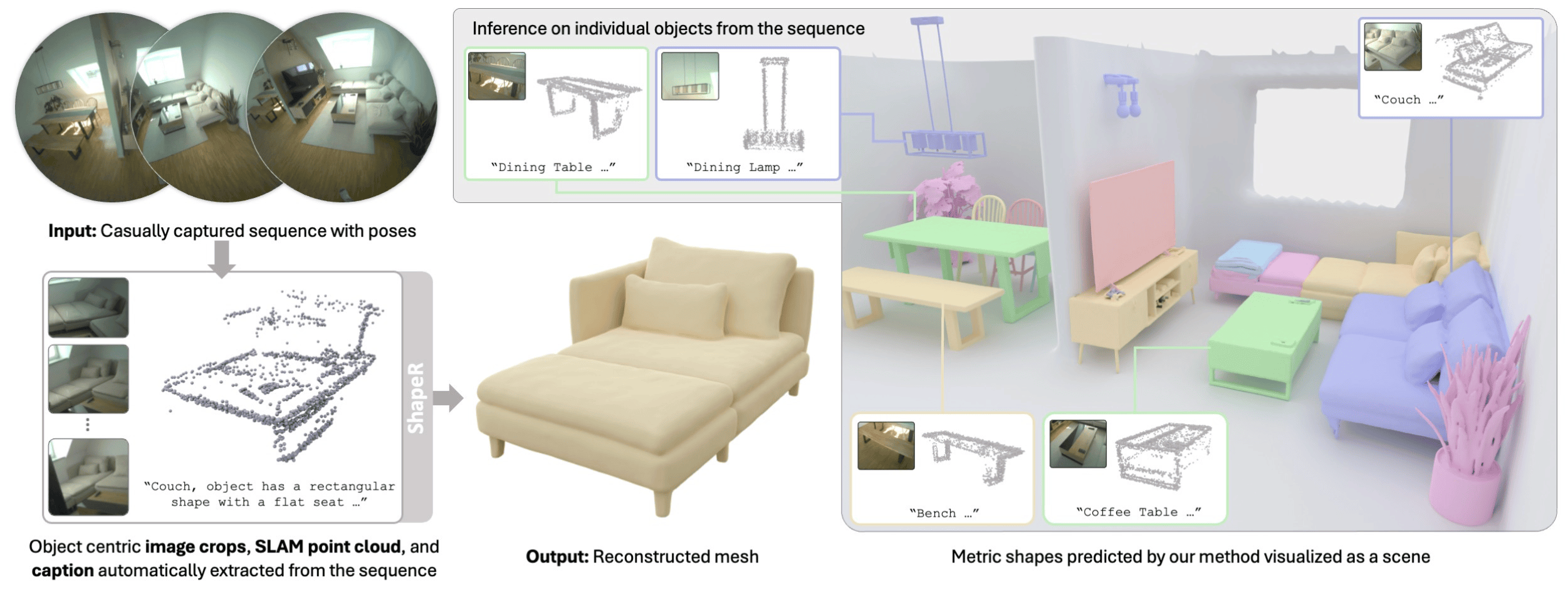
Yawar Siddiqui, Duncan Frost, Samir Aroudj, Armen Avetisyan, Henry Howard-Jenkins, Daniel DeTone, Pierre Moulon, Qirui Wu, Zhengqin Li, Julian Straub, and Richard Newcombe, Jakob Engel
In CVPR (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Jiyeon Han, Ali Mahdavi-Amiri, Hao (Richard) Zhang, Haedong Jeong
In CVPR (2026)
[
![]() Paper
]
Paper
]
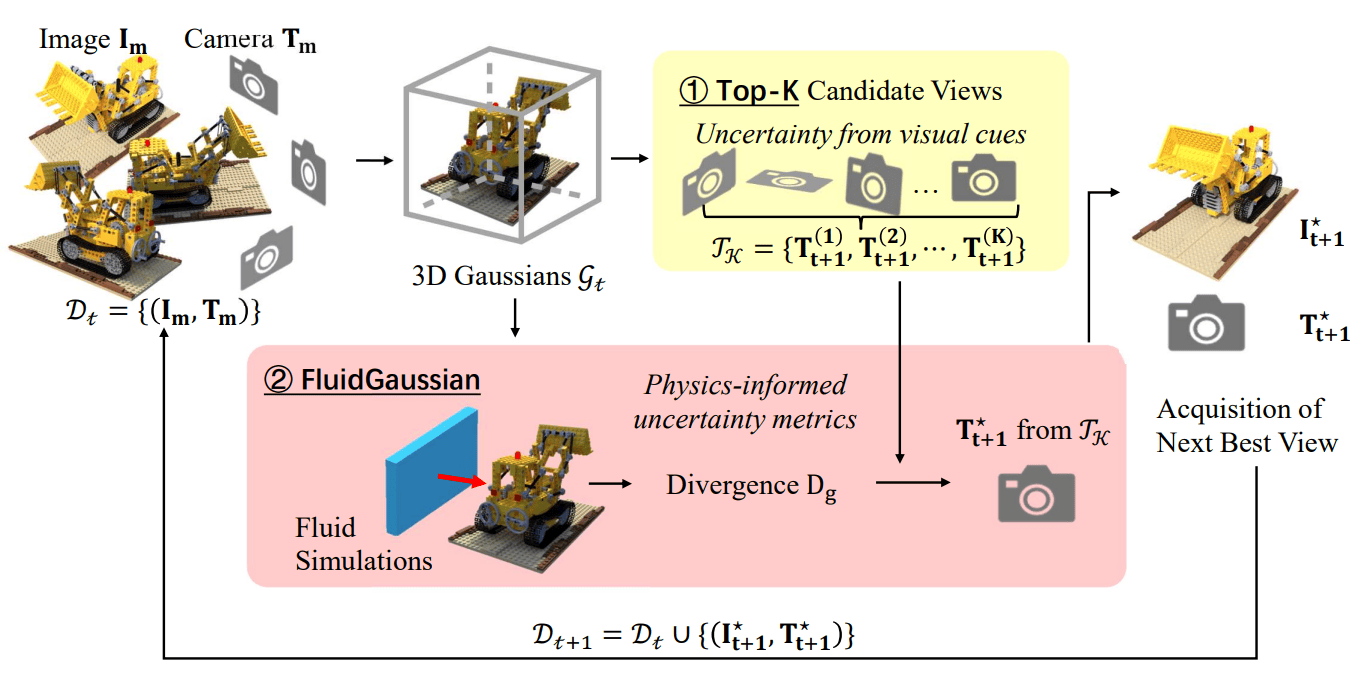
Yuqiu Liu, Jialin Song, Marissa Ramirez de Chanlatte, Rochishnu Chowdhury, Rushil Paresh Desai, Wuyang Chen, Daniel Martin, Michael Mahoney
In CVPR (2026)
[
![]() Paper
]
Paper
]

Sai Raj Kishore Perla, Hao (Richard) Zhang, Ali Mahdavi-Amiri
In Eurographics STAR (2026)
[ ]

Maham Tanveer, Yang Zhou, Simon Nicklaus, Ali Mahdavi-Amiri, Hao (Richard) Zhang, Krishna Kumara Singh, Nanxuan Zhao
In Eurographics (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
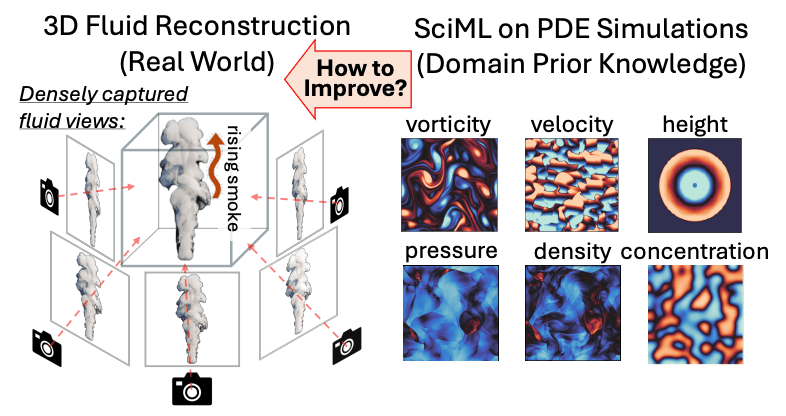
Yuqiu Liu, Jingxuan Xu, Mauricio Soroco, Yunchao Wei, Wuyang Chen
In 3DV (2026)
[
![]() Paper
]
Paper
]
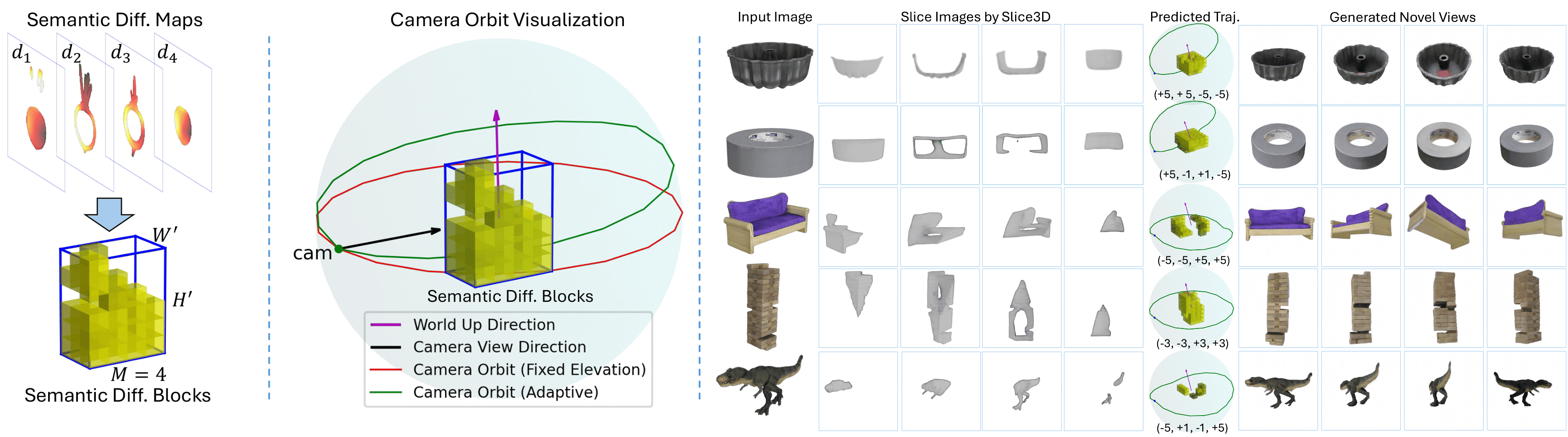
Yizhi Wang, Mingrui Zhao, Hao Zhang
In 3DV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Aditya Vora, Lily Goli, Hao Zhang, Andrea Tagliasacchi
In 3DV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Weikun Peng, Jun Lv, Cewu Lu, Manolis Savva
In 3DV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Xiaohao Sun, Divyam Goel, Angel X. Chang
In 3DV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Hou In Derek Pun, Hou In Ivan Tam, Austin T. Wang, Xiaoliang Huo, Angel X. Chang, Manolis Savva
In 3DV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Hou In Ivan Tam, Hou In Derek Pun, Austin T. Wang, Angel X. Chang, Manolis Savva
In WACV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Denys Iliash, Hanxiao (Shawn) Jiang, Yiming Zhang, Manolis Savva, Angel X. Chang
In WACV (2026)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Qimin Chen, Yuezhi Yang, Wang Yifan, Vladimir G. Kim, Siddhartha Chaudhuri, Hao Zhang, Zhiqin Chen
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sai Raj Kishore Perla, Aditya Vora, Sauradip Nag, Ali Mahdavi-Amiri, Hao (Richard) Zhang
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sauradip Nag, Daniel Cohen-Or, Hao (Richard) Zhang, Ali Mahdavi-Amiri
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Chen Tessler, Yifeng Jiang, Erwin Coumans, Zhengyi Luo, Gal Chechik, Xue Bin Peng
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Ziyu Zhang, Sergey Bashkirov, Dun Yang, Yi Shi, Michael Taylor, Xue Bin Peng
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yuxuan Mu, Hung Yu Ling, Yi Shi, Ismael Baira Ojeda, Pengcheng Xi, Chang Shu, Fabio Zinno, Xue Bin Peng
In SIGGRAPH Asia (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yanjie Ze, Zixuan Chen, João Pedro Araújo, Zi-ang Cao, Xue Bin Peng, Jiajun Wu, C. Karen Liu
In CoRL (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zixuan Chen, Xialin He, Yen-Jen Wang, Qiayuan Liao, Yanjie Ze, Zhongyu Li, S. Shankar Sastry, Jiajun Wu, Koushil Sreenath, Saurabh Gupta, Xue Bin Peng
In IROS (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Shrisudhan Govindarajan, Daniel Rebain, Kwang Moo Yi, Andrea Tagliasacchi
In ICCV (Highlight) (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Shakiba Kheradmand, Delio Vicini, George Kopanas, Dmitry Lagun, Kwang Moo Yi, Mark J. Matthews, Andrea Tagliasacchi
In ICCV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Lily Goli, Sara Sabour, Mark J. Matthews, Marcus A Brubaker, Dmitry Lagun, Alec Jacobson, David J. Fleet, Saurabh Saxena, Andrea Tagliasacchi
In ICCV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Han-Hung Lee, Qinghong Han, Angel X. Chang
In ICCV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Qirui Wu, Denys Iliash, Daniel Ritchie, Manolis Savva, Angel X. Chang
In ICCV (Highlight) (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Junru Lin, Chirag Vashist, Mikaela Angelina Uy, Colton Stearns, Xuan Luo, Leonidas Guibas, Ke Li
In ICCV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Michael Xu, Yi Shi, KangKang Yin, Xue Bin Peng
In SIGGRAPH conference (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Changhao Li, Yu Xin, Xiaowei Zhou, Ariel Shamir, Hao Zhang, Ligang Liu, Ruizhen Hu
In SIGGRAPH conference (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yilin Liu, Duoteng Xu, Xingyao Yu, Xiang Xu, Daniel Cohen-Or, Hao Zhang, and Hui Huang
In SIGGRAPH journal (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Amir Alimohammadi, Aryan Mikaeili, Sauradip Nag, Negar Hassanpour, Andrea Tagliasacchi, Ali Mahdavi-Amiri
In SIGGRAPH (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Qirui Huang, Runze Zhang, Kangjun Liu, Minglun Gong, Hao Zhang, and Hui Huang
In CVPR (Highlight) (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yuxiang Fu, Qi Yan, Lele Wang, Ke Li, Renjie Liao
In CVPR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Kaichen Yang;Junjie Cao;Zeyu Bai;Zhixun Su;Andrea Tagliasacchi
In CVPR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B. Lindell, Sergey Tulyakov
In CVPR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Austin T. Wang, Zeming Gong, Angel X. Chang
In ACL (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
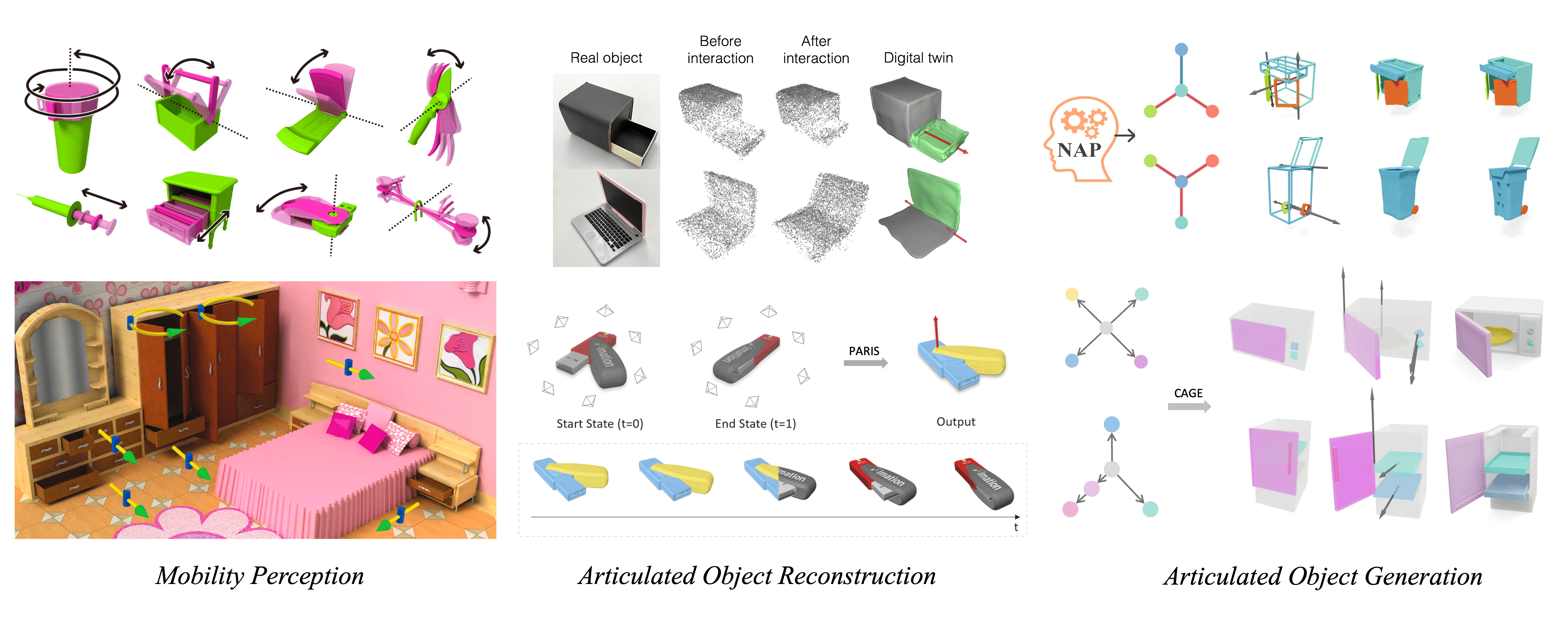
Jiayi Liu, Manolis Savva, and Ali Mahdavi-Amiri
In Eurographics STAR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Dingdong Yang, Yizhi Wang, Konrad Schindler, Ali Mahdavi-Amiri, and Hao Zhang
In ICLR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
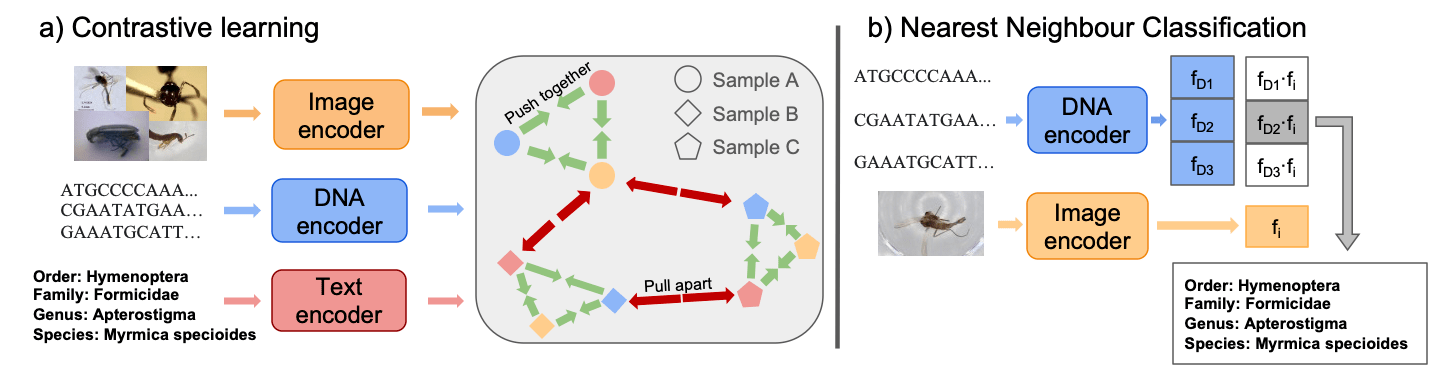
Zeming Gong, Austin T. Wang, Xiaoliang Huo, Joakim Bruslund Haurum, Scott C Lowe, Graham W Taylor, Angel X. Chang
In ICLR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
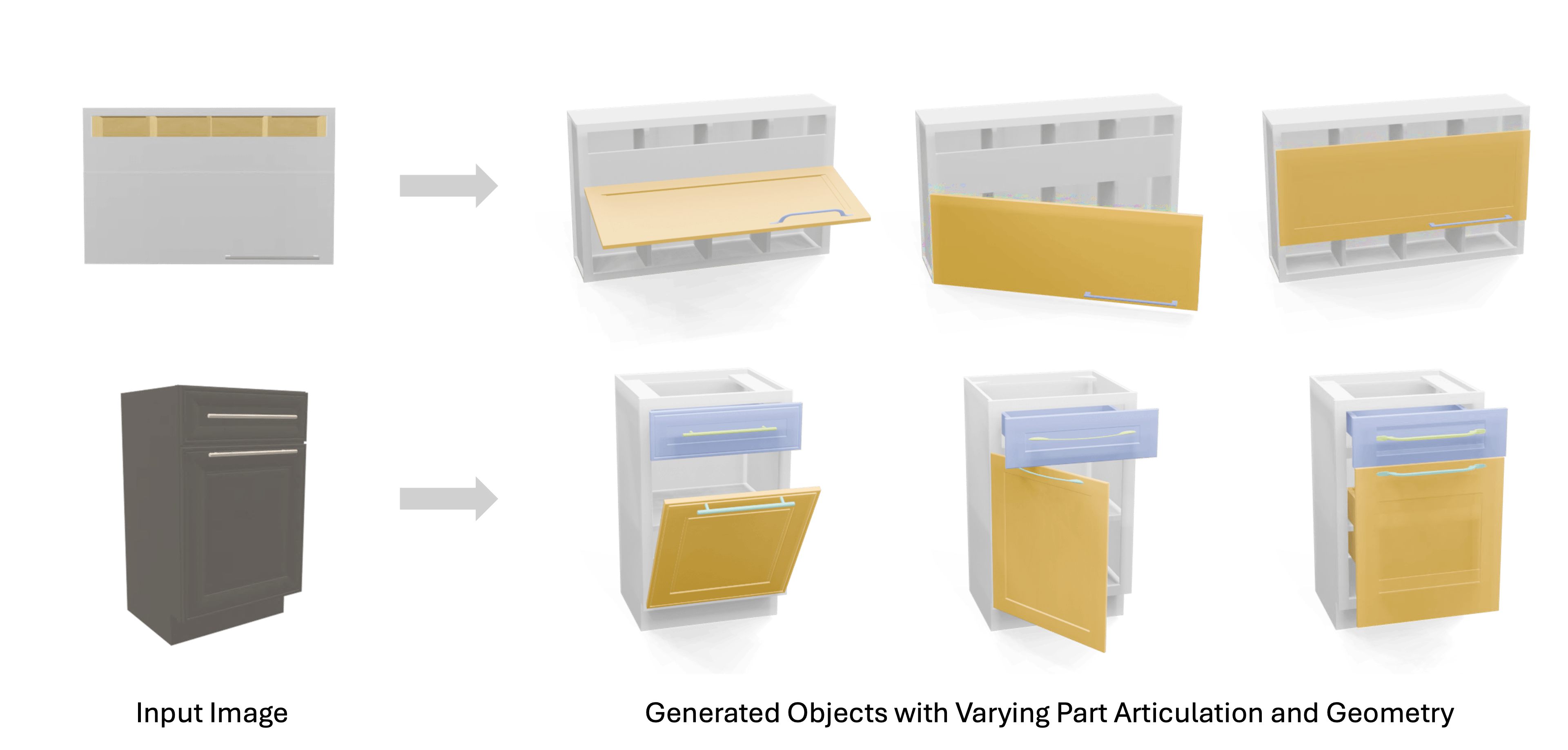
Jiayi Liu, Denys Iliash, Angel X. Chang, Manolis Savva, Ali Mahdavi-Amiri
In ICLR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
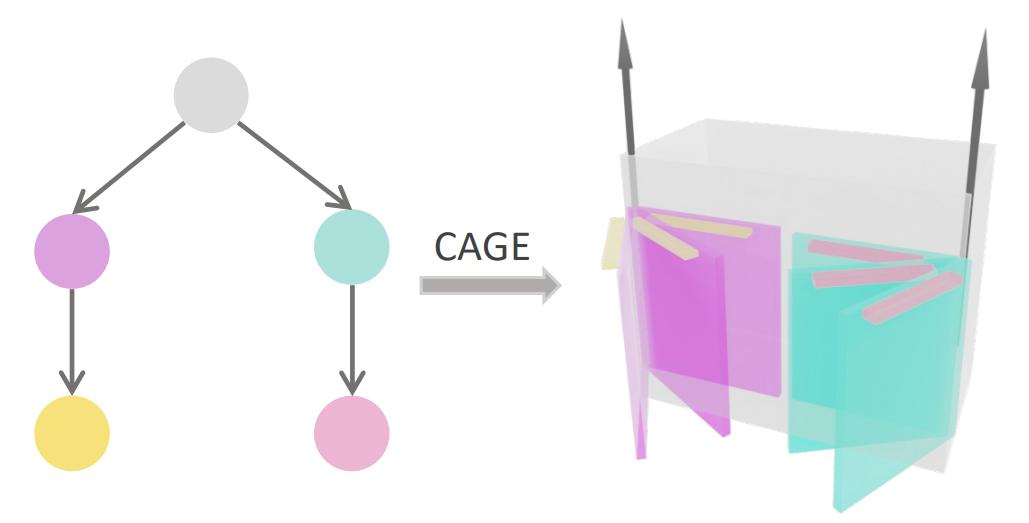
Han-Hung Lee, Yiming Zhang, Angel X. Chang
In ICLR (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Hou In Ivan Tam, Hou In Derek Pun, Austin T. Wang, Angel X. Chang, Manolis Savva
In 3DV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Xingguang Yan, Han-Hung Lee, Ziyu Wan, Angel X. Chang
In 3DV (2025)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Chris Careaga, Yağız Aksoy
In SIGGRAPH Asia (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Chen Tessler, Yunrong Guo, Ofir Nabati, Gal Chechik, Xue Bin Peng
In SIGGRAPH Asia 2024 (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Qirui Wu, Sonia Raychaudhuri, Daniel Ritchie, Manolis Savva, Angel X. Chang
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Sebastian Dille, Chris Careaga, Yağız Aksoy
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Weiwei Sun, Eduard Trulls, Yang-Che Tseng, Sneha Sambandam, Gopal Sharma, Andrea Tagliasacchi, Kwang Moo Yi
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Gopal Sharma, Daniel Rebain, Kwang Moo Yi, Andrea Tagliasacchi
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Shrisudhan Govindarajan, Zeno Sambugaro, Ahan Shabhanov, Towaki Takikawa, Weiwei Sun, Daniel Rebain, Nicola Conci, Kwang Moo Yi, Andrea Tagliasacchi
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
###

Sherwin Bahmani, Xian Liu, Yifan Wang, Ivan Skorokhodov, Victor Rong, Ziwei Liu, Xihui Liu, Jeong Joon Park, Sergey Tulyakov, Gordon Wetzstein, Andrea Tagliasacchi, David B. Lindell
In ECCV ()
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Mingrui Zhao, Yizhi Wang, Fenggen Yu, Changqing Zou, Ali Mahdavi-Amiri
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Hongwei Yi, Justus Thies, Michael J. Black, Xue Bin Peng, Davis Rempe
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Qimin Chen, Zhiqin Chen, Vladimir G. Kim, Noam Aigerman, Hao Zhang, Siddhartha Chaudhuri
In ECCV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhiqin Chen, Qimin Chen, Hang Zhou, Hao Zhang
In SIGGRAPH (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

S. Mahdi H. Miangoleh, Mahesh Reddy, Yağız Aksoy
In SIGGRAPH (2024)
[ ]
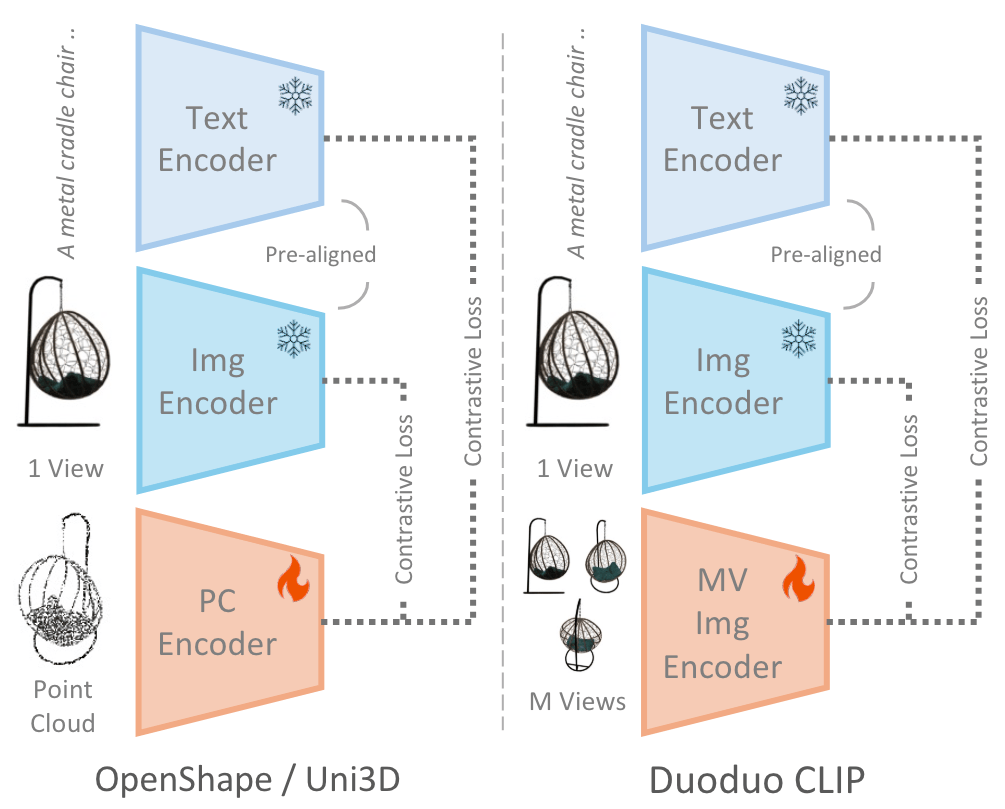
Xiang Xu, Joseph G. Lambourne, Pradeep Kumar Jayaraman, Zhengqing Wang, Karl D.D. Willis, Yasutaka Furukawa
In SIGGRAPH (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yi Shi, Jingbo Wang, Xuekun Jiang, Bingkun Lin, Bo Dai, Xue Bin Peng
In SIGGRAPH (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Jordan Juravsky, Yunrong Guo, Sanja Fidler, Xue Bin Peng
In SIGGRAPH (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Setareh Cohan, Guy Tevet, Daniele Reda, Xue Bin Peng, Michiel van de Panne
In SIGGRAPH (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
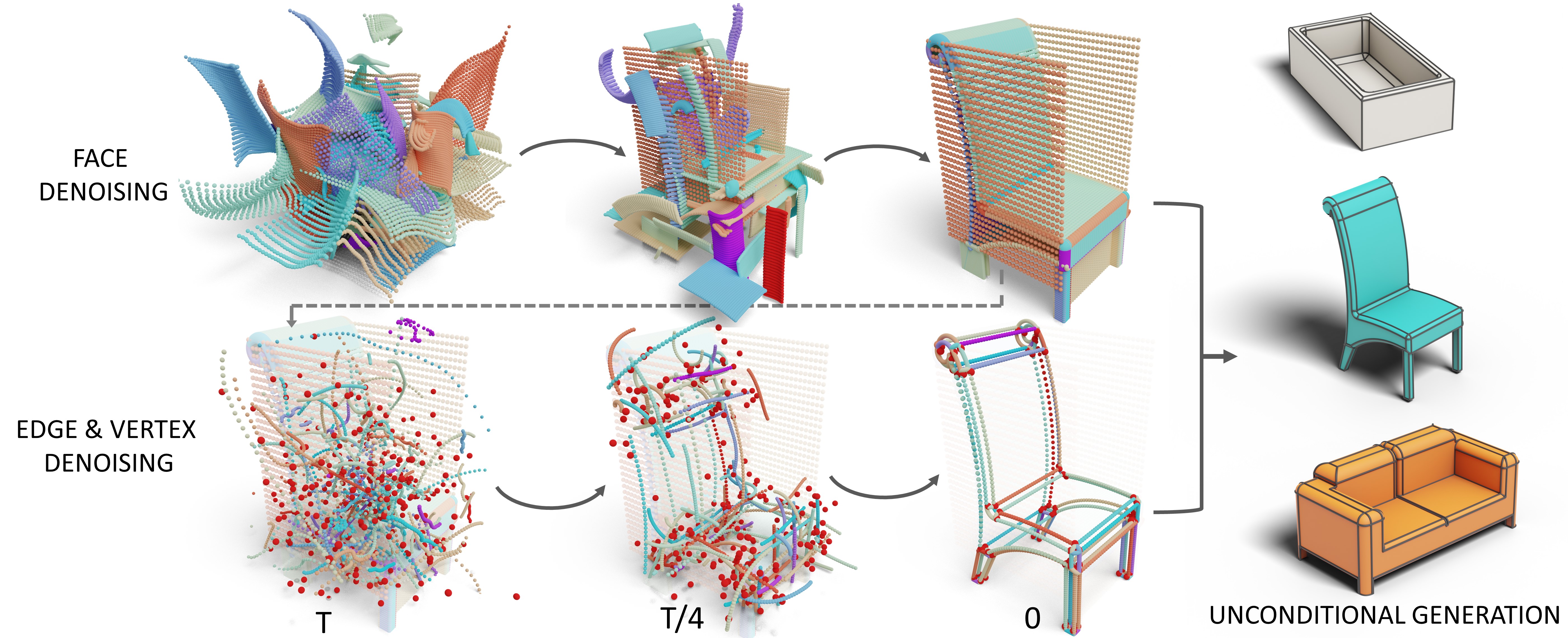
Daniel Rebain, Soroosh Yazdani, Kwang Moo Yi, Andrea Tagliasacchi
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Lily Goli, Cody Reading, Silvia Sellan, Alec Jacobson, Andrea Tagliasacchi
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, Kwang Moo Yi
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Helge Rhodin, Andrea Tagliasacchi, Kwang Moo Yi
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Ahan Shabanov, Shrisudhan Govindarajan, Cody Reading, Daniel Rebain, Kwang Moo Yi, Andrea Tagliasacchi
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

David Charatan, Sizhe Li, Andrea Tagliasacchi, Vincent Sitzmann
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, David Lindell
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
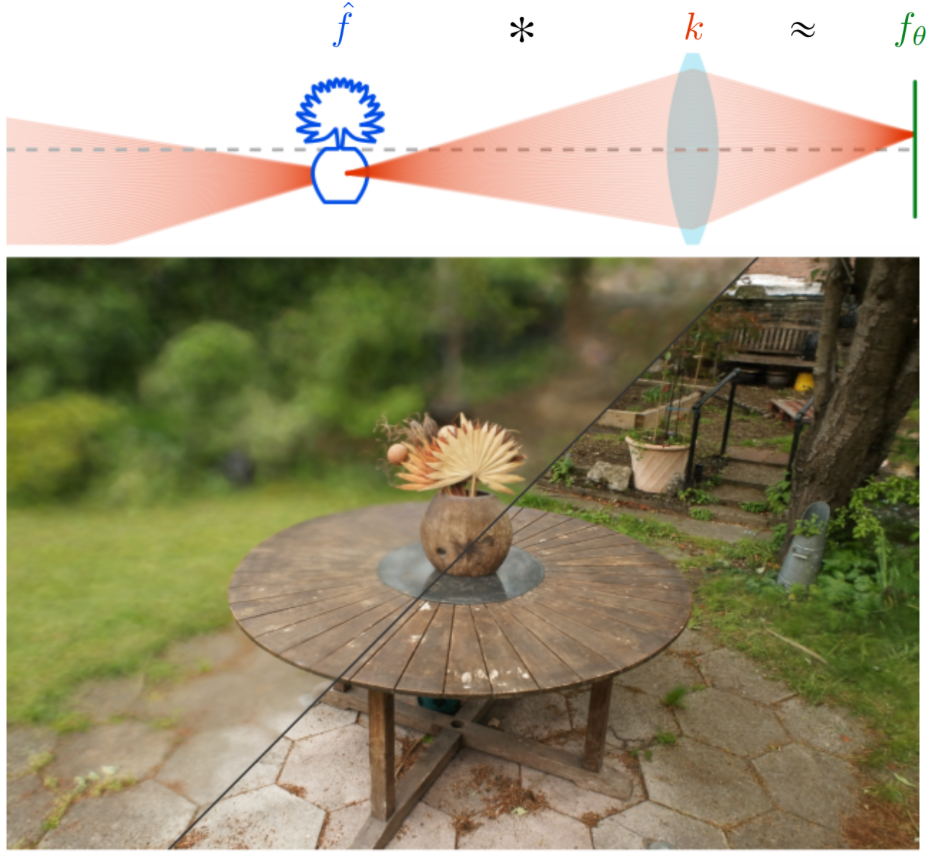
Jiayi Liu, Hou In Ivan Tam, Ali Mahdavi-Amiri, Manolis Savva
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
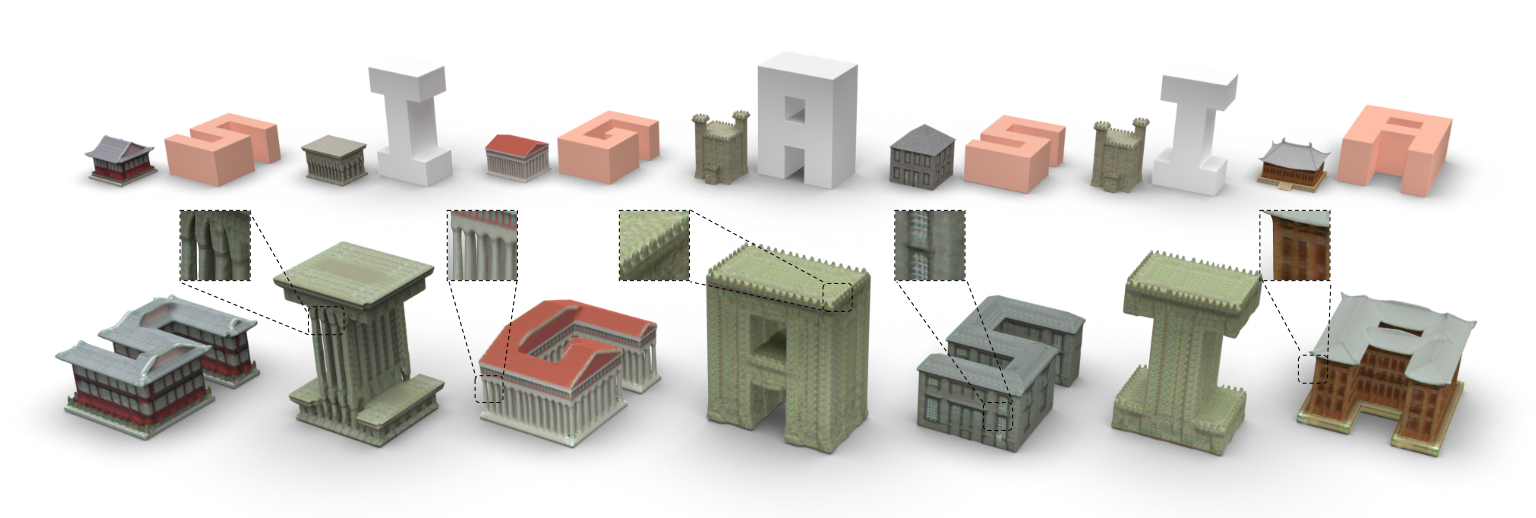
Yizhi Wang, Wallace Lira, Wenqi Wang, Ali Mahdavi-Amiri, Hao Zhang
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Shichong Peng, Yanshu Zhang, Ke Li
In CVPR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Jonah Philion, Xue Bin Peng, Sanja Fidler
In ICLR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Han-Hung Lee, Manolis Savva, Angel X Chang
In Eurographics STAR (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
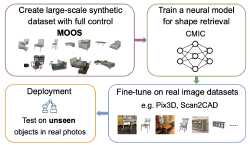
Qirui Wu, Daniel Ritchie, Manolis Savva, Angel X Chang
In 3DV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
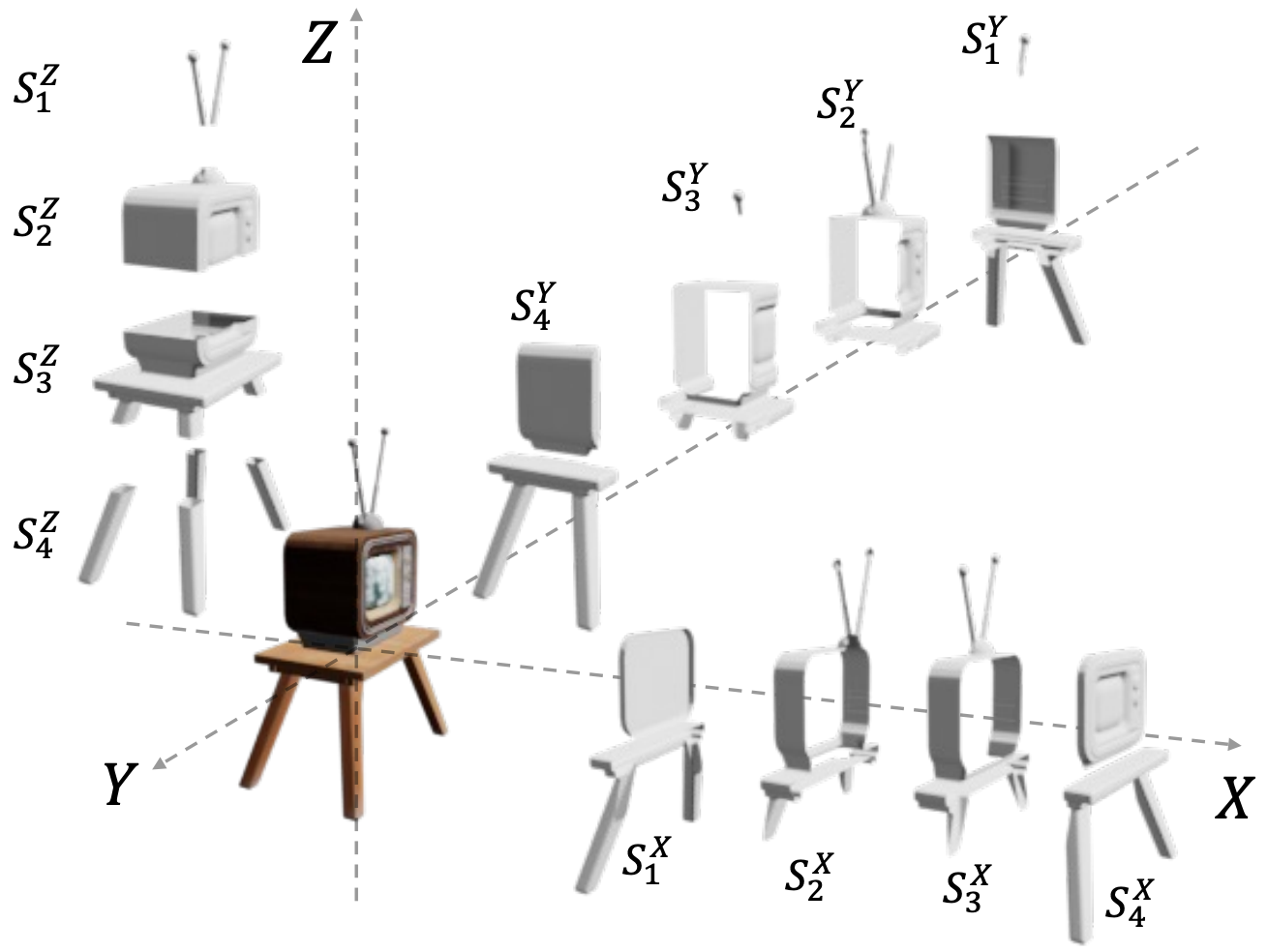
Xiaohao Sun, Hanxiao Jiang, Manolis Savva, Angel X Chang
In 3DV (2024)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Chris Careaga, S. Mahdi H. Miangoleh, Yağız Aksoy
In SIGGRAPH Asia (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
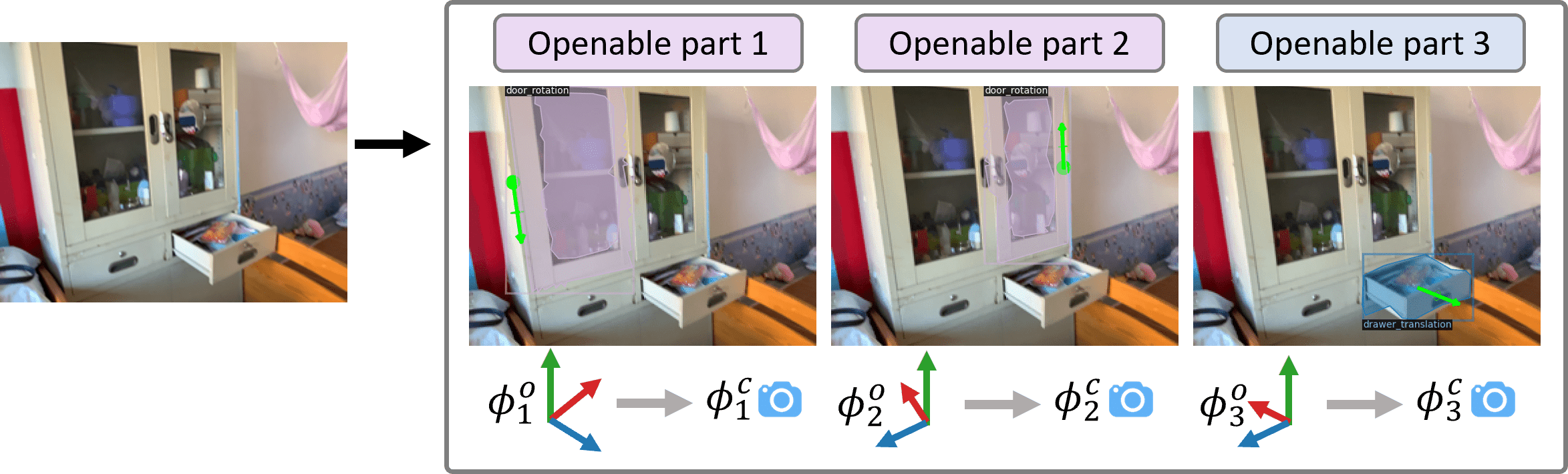
Qimin Chen, Zhiqin Chen, Hang Zhou, Hao Zhang
In SIGGRAPH Asia (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Aditya Vora, Akshay Gadi Patil, Hao (Richard) Zhang
In SIGGRAPH Asia (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
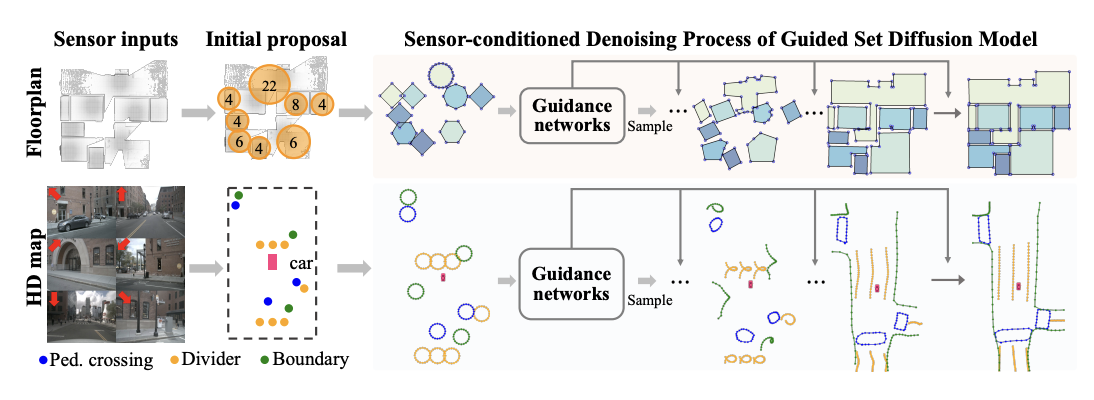
Jiacheng Chen, Ruizhi Deng, Yasutaka Furukawa
In SIGGRAPH Asia (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
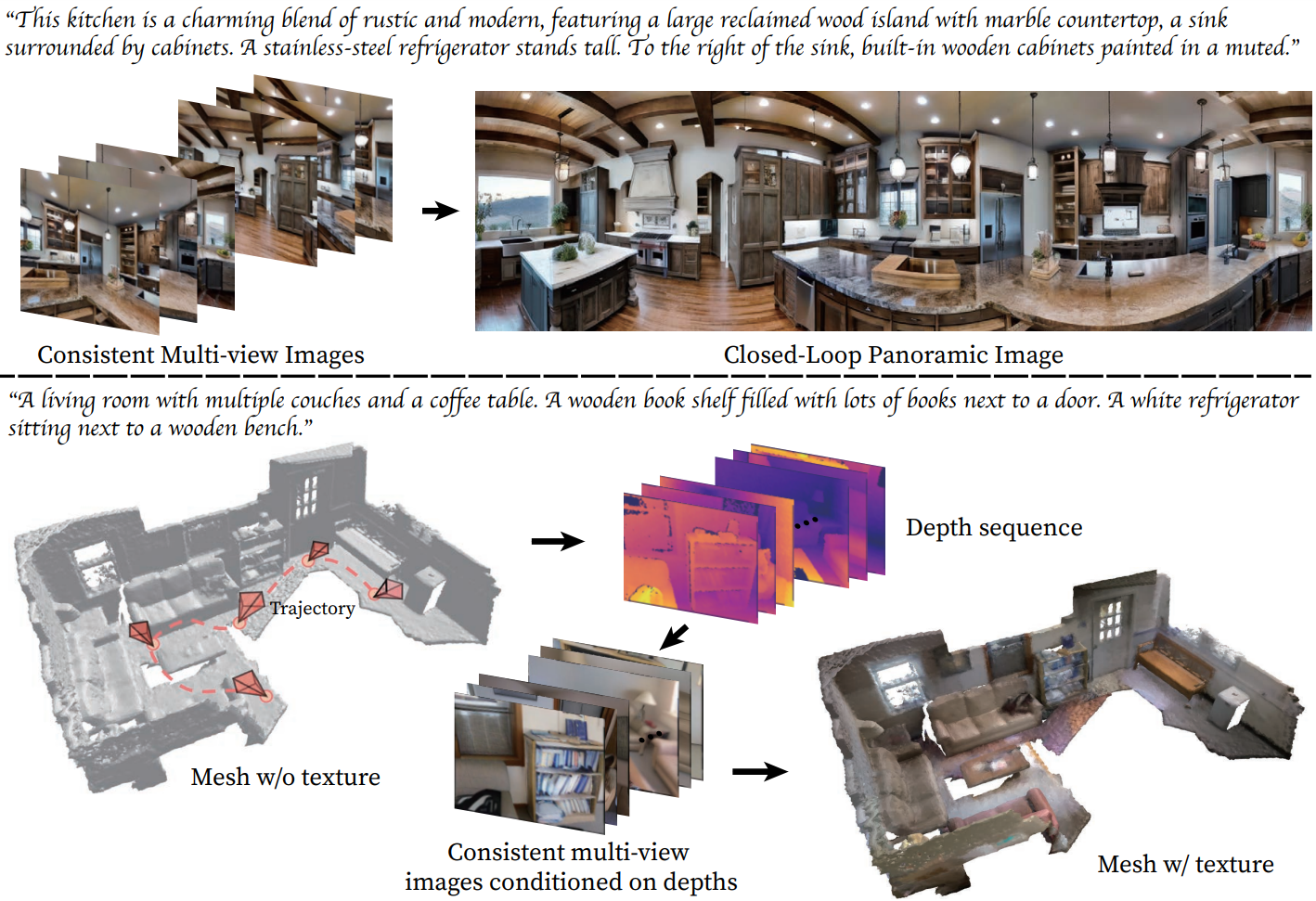
Shitao Tang, Fuyang Zhang, Jiacheng Chen, Peng Wang, Yasutaka Furukawa
In NeurIPS (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Fangcheng Zhong, Kyle Fogarty, Param Hanji, Tianhao Wu, Alejandro Sztrajman, Andrew Spielberg, Andrea Tagliasacchi, Petra Bosilj, Cengiz Oztireli
In NeurIPS (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Eric Hedlin, Gopal Sharma, Shweta Mahajan, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, Kwang Moo Yi
In NeurIPS (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zahra Gharaee, Zeming Gong, Nicholas Pellegrino, Iuliia Zarubiieva, Joakim Bruslund Haurum, Scott C Lowe, Jaclyn TA McKeown, Chris CY Ho, Joschka McLeod, Yi-Yun C Wei, Jireh Agda, Sujeevan Ratnasingham, Dirk Steinke, Angel X. Chang, Graham W Taylor, Paul Fieguth
In NeurIPS Datasets and Benchmarks Track (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
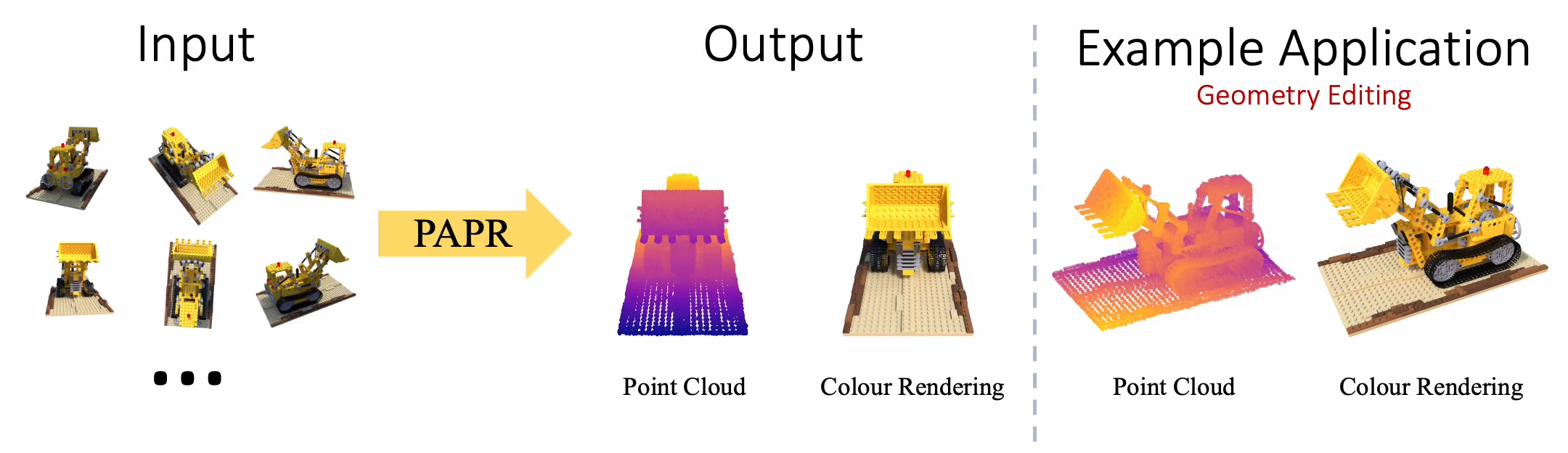
Yanshu Zhang, Shichong Peng, Seyed Alireza Moazenipourasil, Ke Li
In NeurIPS (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sepidehsadat Hosseini, Mohammad Amin Shabani, Saghar Irandoust, Yasutaka Furukawa
In NeurIPS (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
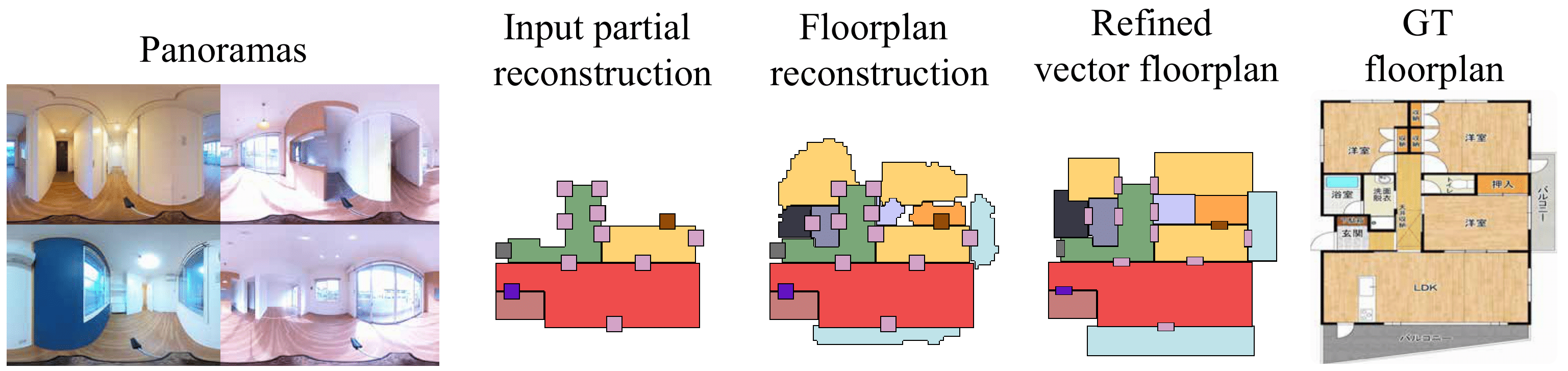
Sepidehsadat Hosseini, Yasutaka Furukawa
In BMVC (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Sriram Yenamandra, Arun Ramachandran, Karmesh Yadav, Austin Wang, Mukul Khanna, Theo Gervet, Tsung-Yen Yang, Vidhi Jain, Alexander William Clegg, John Turner, Zsolt Kira, Manolis Savva, Angel X. Chang, Devendra Chaplot, Dhruv Batra, Roozbeh Mottaghi, Yonatan Bisk, Chris Paxton
In CoRL (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Chris Careaga and Yağız Aksoy
In ACM Transactions on Graphics, Vol. 43, Issue 1, Article 12 (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
Enrico Cancelli, Tommaso Campari, Luciano Serafini, Angel X. Chang, Lamberto Ballan
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Dave Zhenyu Chen, Ronghang Hu, Xinlei Chen, Matthias Nießner, Angel X. Chang
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
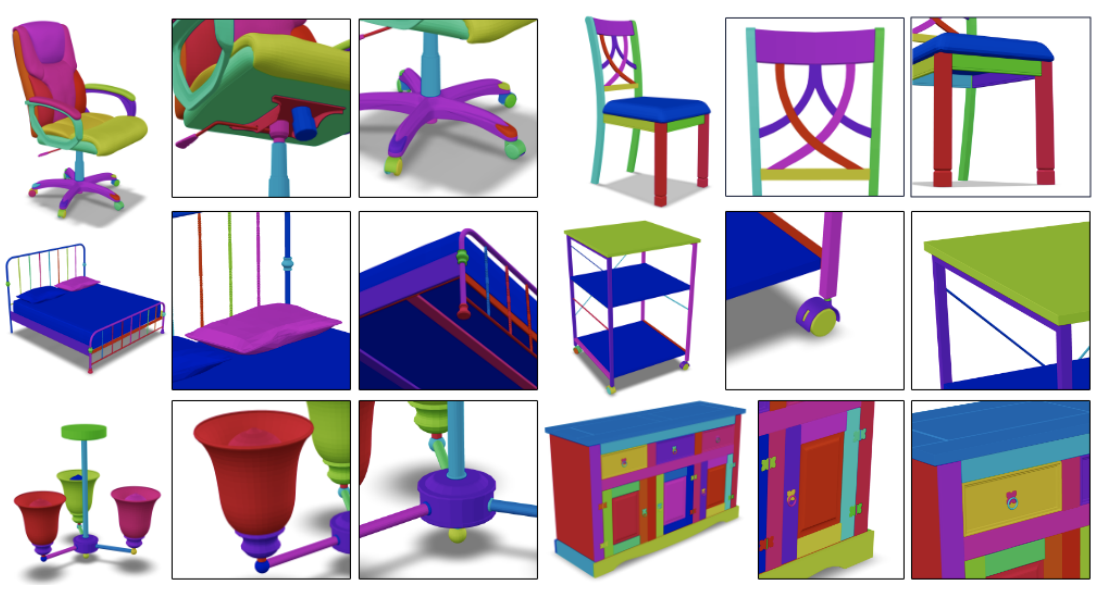
Fenggen Yu, Yiming Qian, Francisca Gil-Ureta, Brian Jackson, Eric Bennett, and Hao Zhang
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Jiayi Liu, Ali Mahdavi-Amiri, Manolis Savva
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
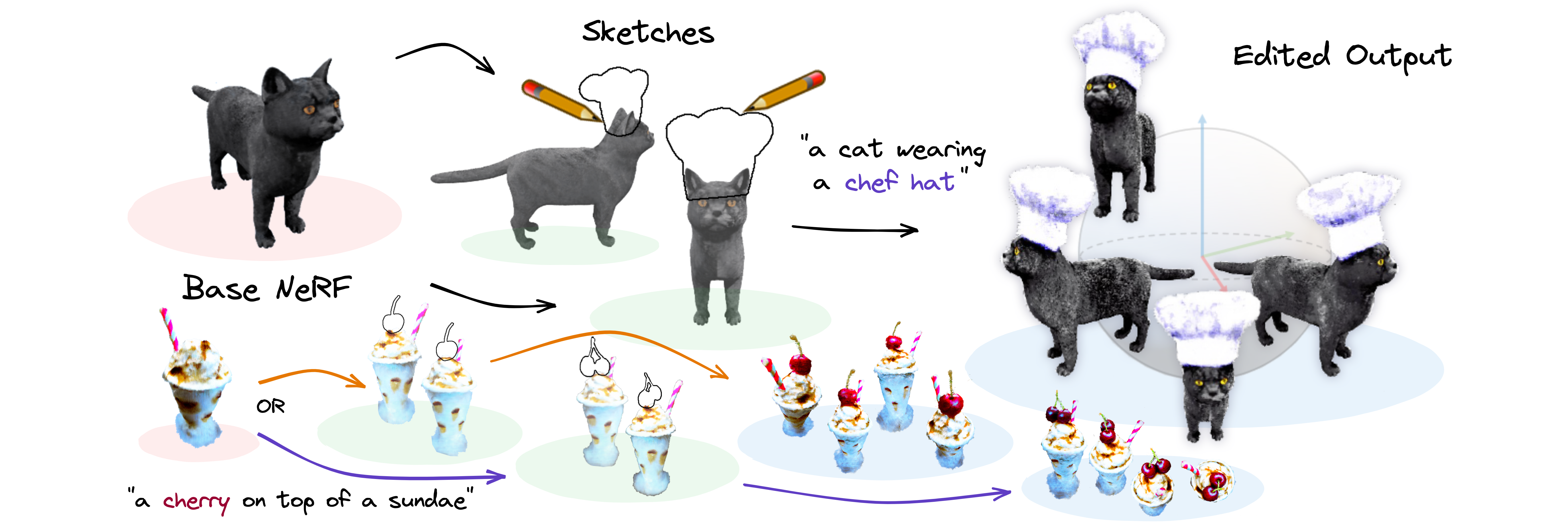
Aryan Mikaeili, Or Perel, Mehdi Safaee, Daniel Cohen-Or, Ali Mahdavi-Amiri
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
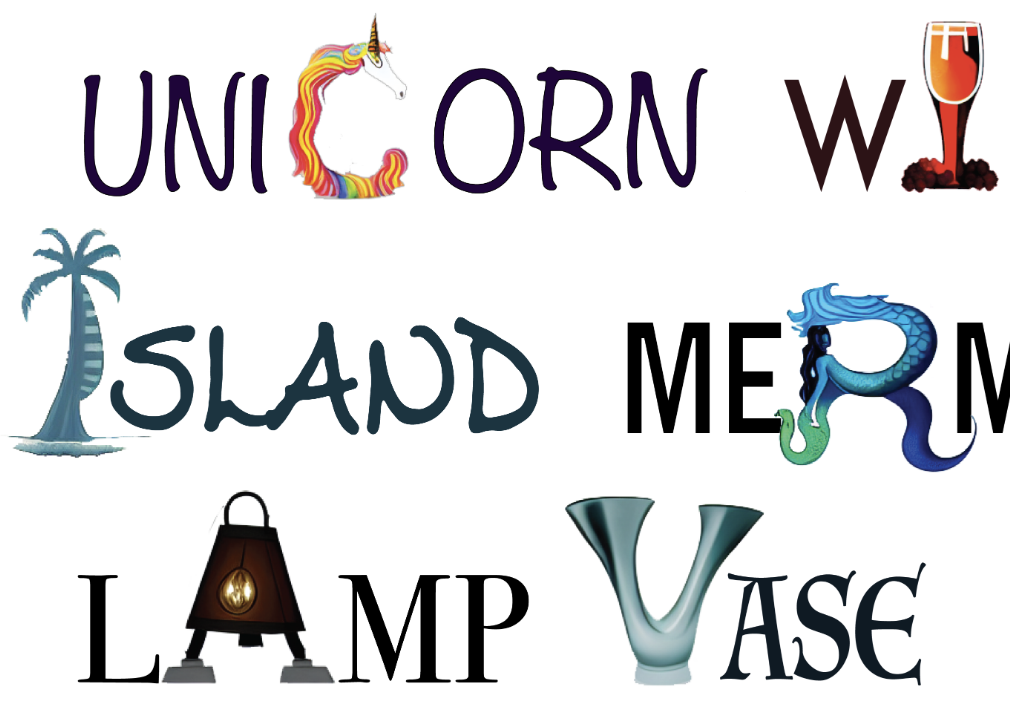
Maham Tanveer, Yizhi Wang, Ali Mahdavi-Amiri, Hao Zhang
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yiming Zhang, ZeMing Gong, Angel X. Chang
In ICCV (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Haotian Zhang, Ye Yuan, Viktor Makoviychuk, Yunrong Guo, Sanja Fidler, Xue Bin Peng, Kayvon Fatahalian
In SIGGRAPH (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Mohamed Hassan, Yunrong Guo, Tingwu Wang, Michael Black, Sanja Fidler, Xue Bin Peng
In SIGGRAPH (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Chen Tessler, Yoni Kasten, Yunrong Guo, Shie Mannor, Gal Chechik, Xue Bin Peng
In SIGGRAPH (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

S. Mahdi H. Miangoleh, Zoya Bylinskii, Eric Kee, Eli Shechtman, Yağız Aksoy
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Sepideh Sarajian Maralan, Chris Careaga, and Yağız Aksoy
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
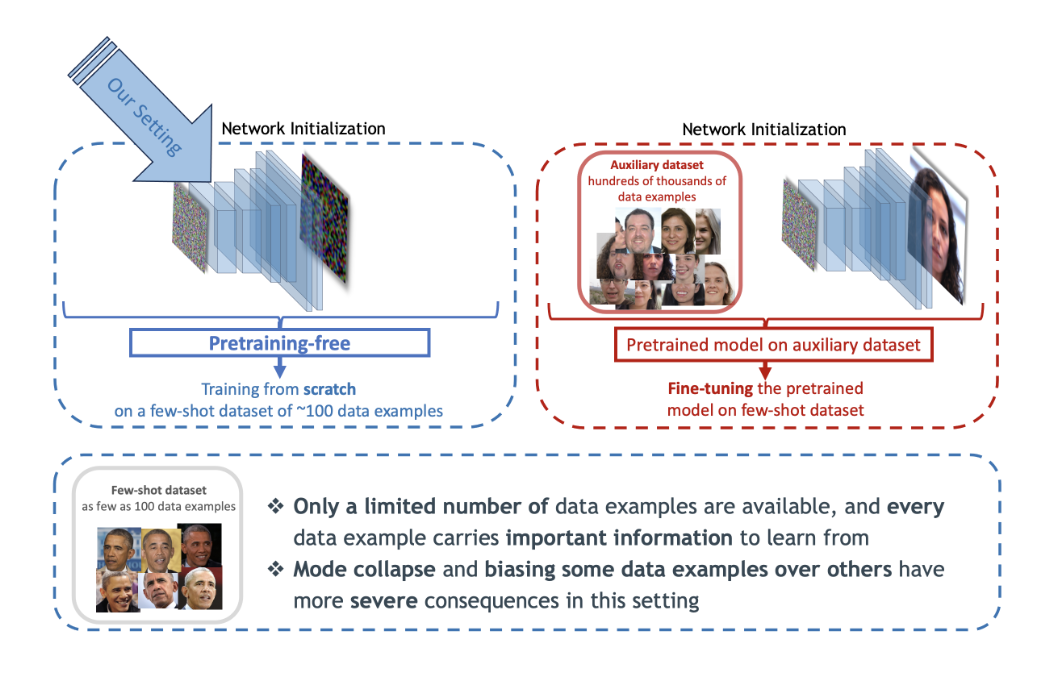
Mehran Aghabozorgi, Shichong Peng, Ke Li
In ICLR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Erik Wijmans, Manolis Savva, Irfan Essa, Stefan Lee, Ari S Morcos, Dhruv Batra
In ICLR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
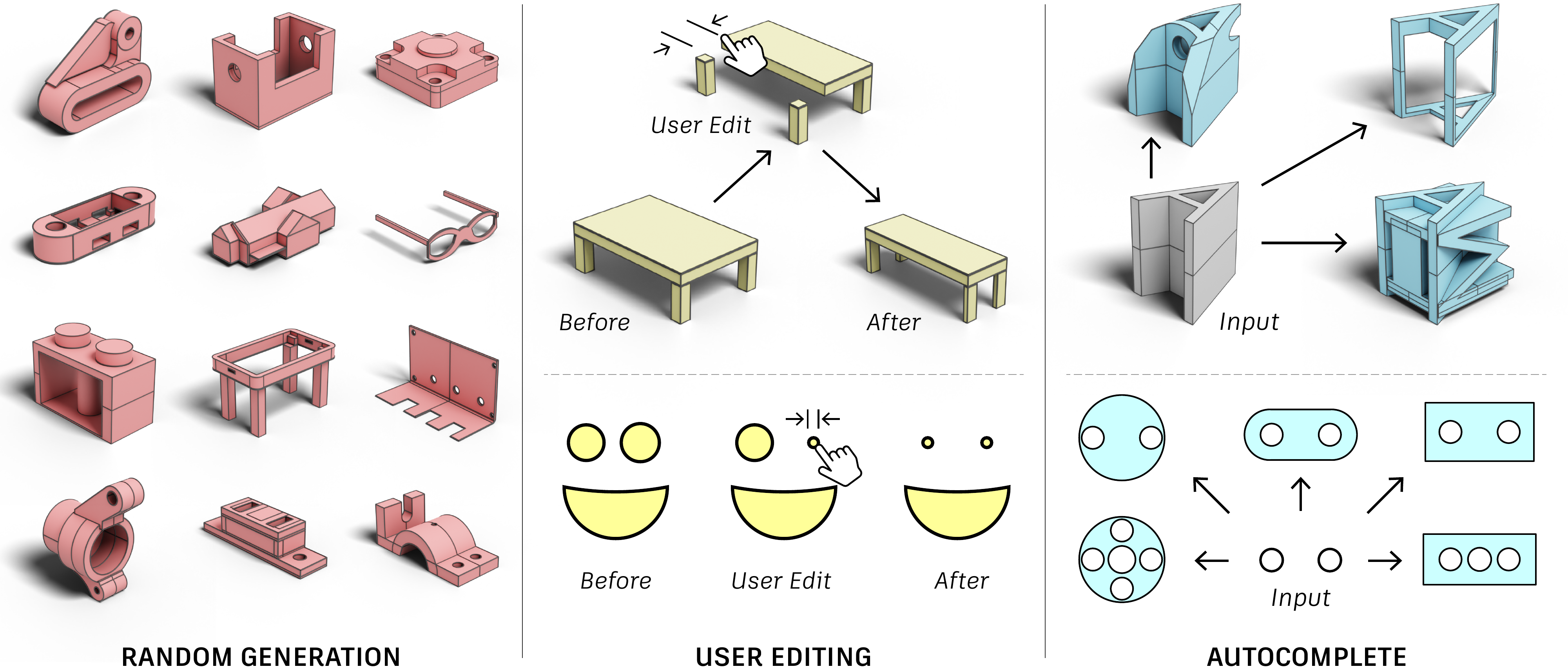
Xiang Xu, Pradeep Kumar Jayaraman, Joseph G. Lambourne, Karl D.D. Willis, Yasutaka Furukawa
In ICML (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, Alexander William Clegg, Devendra Singh Chaplot
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
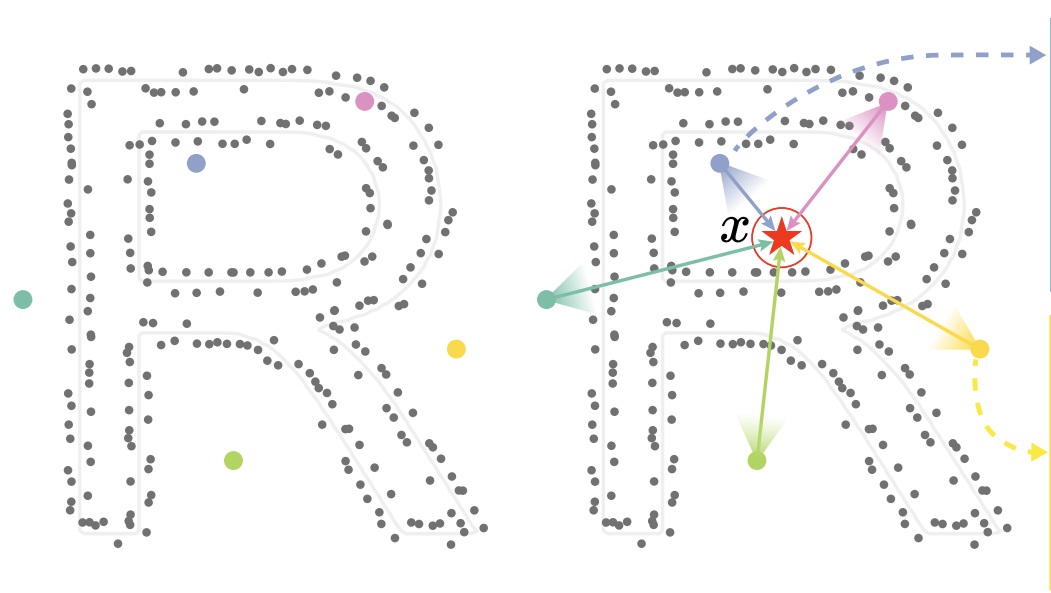
Yizhi Wang, Zeyu Huang, Ariel Shamir, Hui Huang, Hao Zhang, and Ruizhen Hu
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Cristina Vasconcelos, Kevin Swersky, Mark Matthews, Milad Hashemi, Cengiz Oztireli, Andrea Tagliasacchi
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Songyou Peng, Kyle Genova, Chiyu Max Jiang, Andrea Tagliasacchi, Marc Pollefeys, Thomas Funkhouser
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Samarth Sinha, Jason Y. Zhang, Andrea Tagliasacchi, Igor Gilitschenski, David B. Lindell
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Kacper Kania, Stephan J. Garbin, Andrea Tagliasacchi, Virginia Estellers, Kwang Moo Yi, Tomasz Trzcinski, Julien Valentin, Marek Kowalski
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhiqin Chen, Tom Funkhouser, Peter Hedman, Andrea Tagliasacchi
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
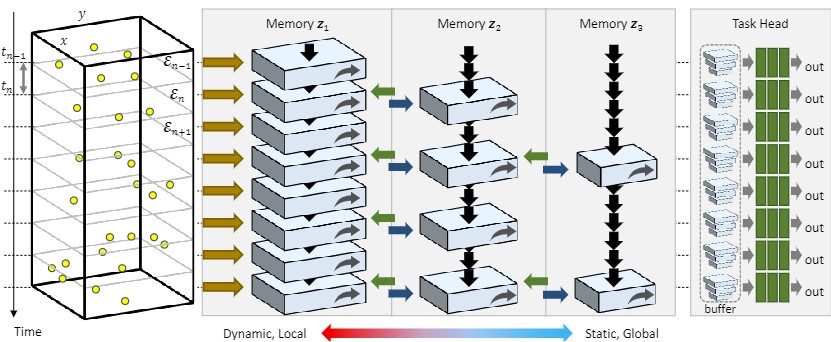
Ryuhei Hamaguchi, Yasutaka Furukawa, Masaki Onishi, and Ken Sakurada
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Amin Shabani, Sepidehsadat Hosseini, and Yasutaka Furukawa
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Shitao Tang, Sicong Tang, Andrea Tagliasacchi, Ping Tan, and Yasutaka Furukawa
In CVPR (2023)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Hang Zhou, Rui Ma, Lingxiao Zhang, Lin Gao, Ali Mahdavi-Amiri, and Hao Zhang
In IEEE Transaction of Visualization and Computer Graphics (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Weilian Song, Mahsa Maleki Abyaneh, Mohammad Amin Shabani, and Yasutaka Furukawa
In ACCV (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yongsen Mao, Yiming Zhang, Hanxiao Jiang, Angel X. Chang, Manolis Savva
In NeurIPS (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Shichong Peng, Alireza Moazeni, Ke Li
In NeurIPS (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Dave Zhenyu Chen, Qirui Wu, Matthias Nießner, Angel X. Chang
In ECCV (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Hanxiao Jiang, Yongsen Mao, Manolis Savva, Angel X. Chang
In ECCV (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

M.Mahdavian, KangKang Yin, and Mo Chen
In IEEE Robotics and Automation Letters (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
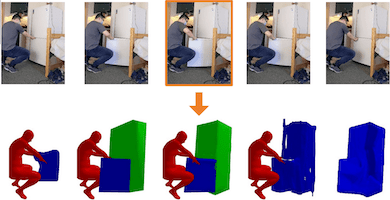
Sanjay Haresh, Xiaohao Sun, Hanxiao Jiang, Angel X. Chang, Manolis Savva
In 3DV (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Zeshi Yang, KangKang Yin, and Libin Liu
In SIGGRAPH (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Yasaman Etesam, Leon Kochiev, Angel X. Chang
In CRV (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Xiang Xu, Karl Willis, Joseph Lambourne, Chin-Yi Cheng, Pradeep Kumar Jayaraman, and Yasutaka Furukawa
In ICML (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
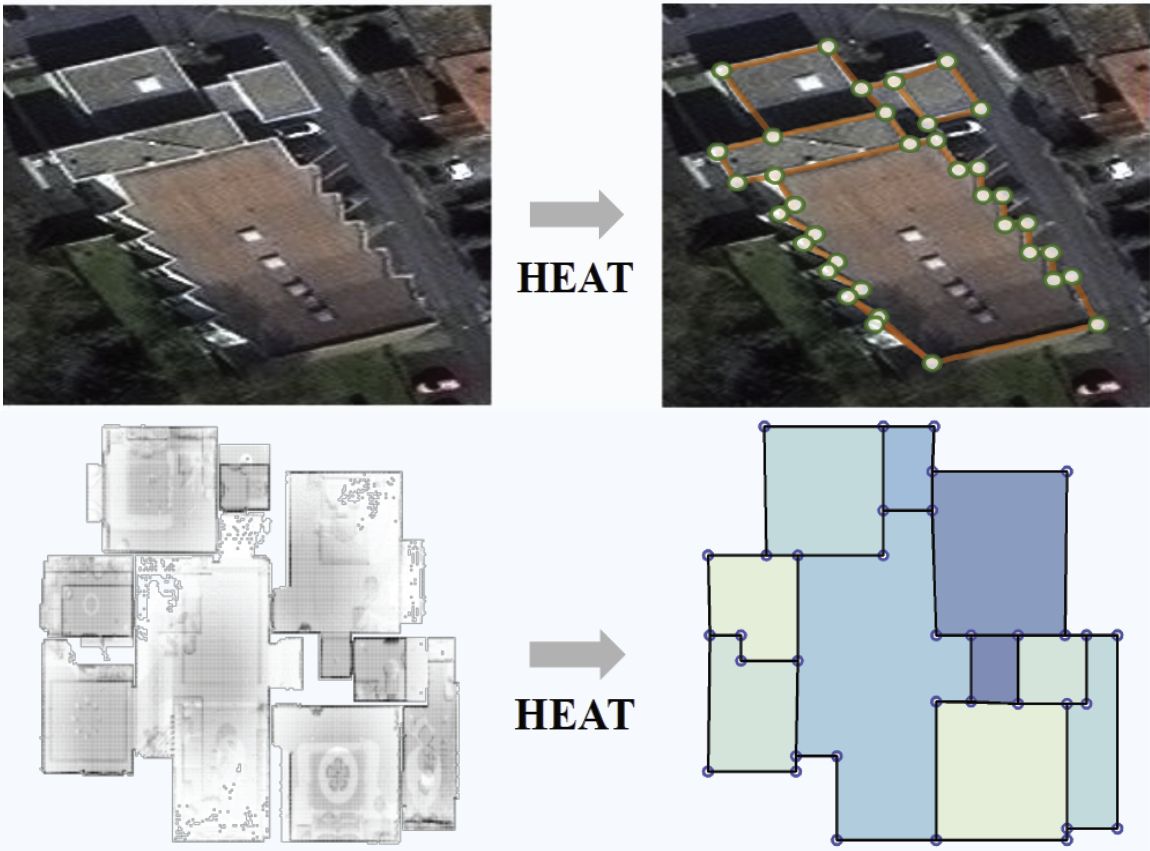
Jiacheng Chen, Yiming Qian, and Yasutaka Furukawa
In CVPR (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Qimin Chen, Johannes Merz, Aditya Sanghi, Hooman Shayani, Ali Mahdavi-Amiri, Hao Zhang
In CVPR (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
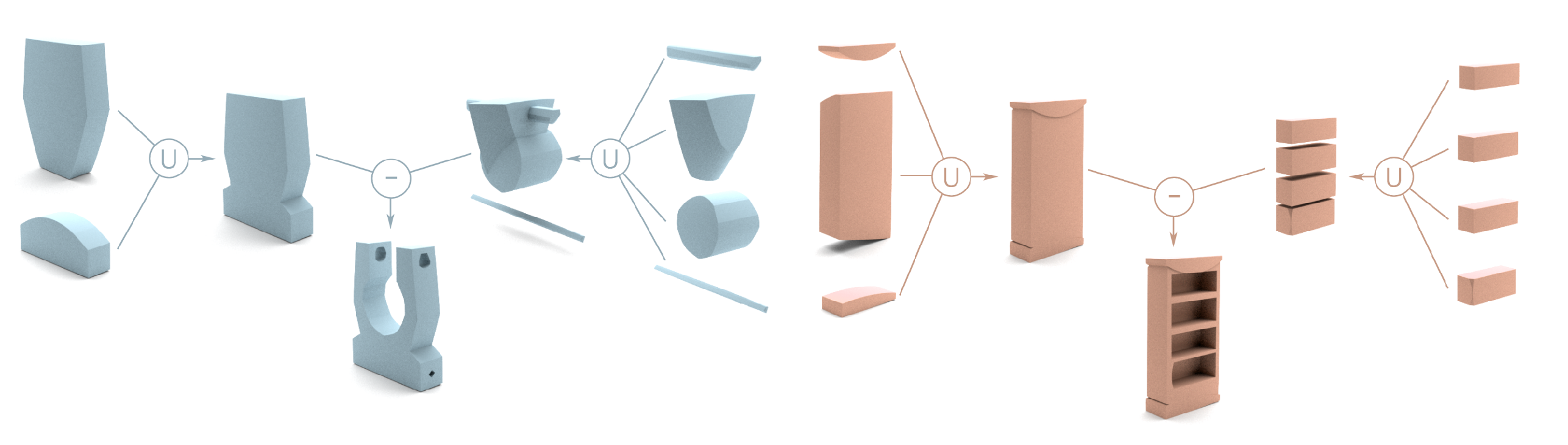
Fenggen Yu, Zhiqin Chen, Manyi Li, Aditya Sanghi, Hooman Shayani, Ali Mahdavi-Amiri, Hao Zhang.
In CVPR (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Himanshu Arora, Saurabh Mishra, Shichong Peng, Ke Li, Ali Mahdavi-Amiri
In CVPR Workshop (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
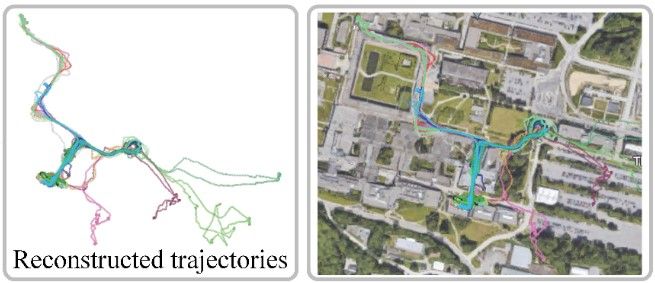
Yiming Qian, Hang Yan, Sachini Herath, Pyojin Kim, and Yasutaka Furukawa
In ICRA (2022)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Santhosh K Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alex Clegg, John Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, Dhruv Batra
In NeurIPS Datasets and Benchmarks Track (2021)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Andrew Szot, Alexander Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Singh Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimír Vondruš, Sameer Dharur, Franziska Meier, Wojciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Jitendra Malik, Manolis Savva, Dhruv Batra
In NeurIPS (2021)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhiqi Yin, Zeshi Yang, Michiel van de Panne, KangKang Yin
In SIGGRAPH (2021)
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Lin Gao, Tong Wu, Yu-Jie Yuan, Ming-Xian Lin, Yu-Kun Lai, and Hao Zhang
In SIGGRAPH Asia (2021)
[
![]() Paper
]
Paper
]
Han Zhang, Yusong Yao, Ke Xie, Chi-Wing Fu, Hao Zhang, and Hui Huang
In SIGGRAPH Asia (2021)
[
![]() Paper
]
Paper
]

Amin Shabani, Weilian Song, Hirochika Fujiki, Makoto Odamaki, and Yasutaka Furukawa
In ICCV (2021)
[
![]() Paper
]
Paper
]
Fuyang Zhang, Sam Xu, Nelson Nauata, and Yasutaka Furukawa
In ICCV (2021)
[
![]() Paper
]
Paper
]
Shivansh Patel, Saim Wani, Unnat Jain, Alexander Schwing, Svetlana Lazebnik, Manolis Savva, Angel X. Chang
In ICCV (2021)
[
![]() Paper
]
Paper
]
Huan Fu, Bowen Cai, Lin Gao, Lingxiao Zhang, Cao Li, Zengqi Xun, Chengyue Sun, Yiyun Fei, Yu Zheng, Ying Li, Yi Liu, Peng Liu, Lin Ma, Le Weng, Xiaohang Hu, Xin Ma, Qian Qian, Rongfei Jia, Binqiang Zhao, and Hao Zhang
In ICCV (2021)
[
![]() Paper
]
Paper
]

Zhiqi Yin, Zeshi Yang, Michiel van de Panne, KangKang Yin
In SIGGRAPH (2021)
[
![]() Paper
]
Paper
]
Li-Ke Ma, Zeshi Yang, Xin Tong, Baining Guo, KangKang Yin
In Eurographics (2021)
[
![]() Paper
]
Paper
]

Feitong Tan, Danhang Tang, Mingsong Dou, Kaiwen Guo, Rohit Pandey, Cem Keskin, Ruofei Du, Deqing Sun, Sofien Bouaziz, Sean Fanello, Ping Tan, Yinda Zhang
In CVPR (2021)
[
![]() Paper
]
Paper
]
Shitao Tang, Chengzhou Tang, Rui Huang, Siyu Zhu, Ping Tan
In CVPR (2021)
[
![]() Paper
]
Paper
]
Ziqian Bai, Zhaopeng Cui, Xiaoming Liu, Ping Tan
In CVPR (2021)
[
![]() Paper
]
Paper
]
Manyi Li, Hao Zhang
In CVPR (2021)
[
![]() Paper
]
Paper
]

Zhiqin Chen, Vladimir Kim, Matthew Fisher, Noam Aigerman, Hao Zhang, and Siddhartha Chaudhuri
In CVPR (oral presentation) (2021)
[
![]() Paper
]
Paper
]

Dave Zhenyu Chen, Ali Gholami, Matthias Nießner, Angel X. Chang
In CVPR (2021)
[
![]() Paper
]
Paper
]
Akshay Gadi Patil, Manyi Li, Matthew Fisher, Manolis Savva, Hao Zhang
In CVPR (2021)
[
![]() Paper
]
Paper
]
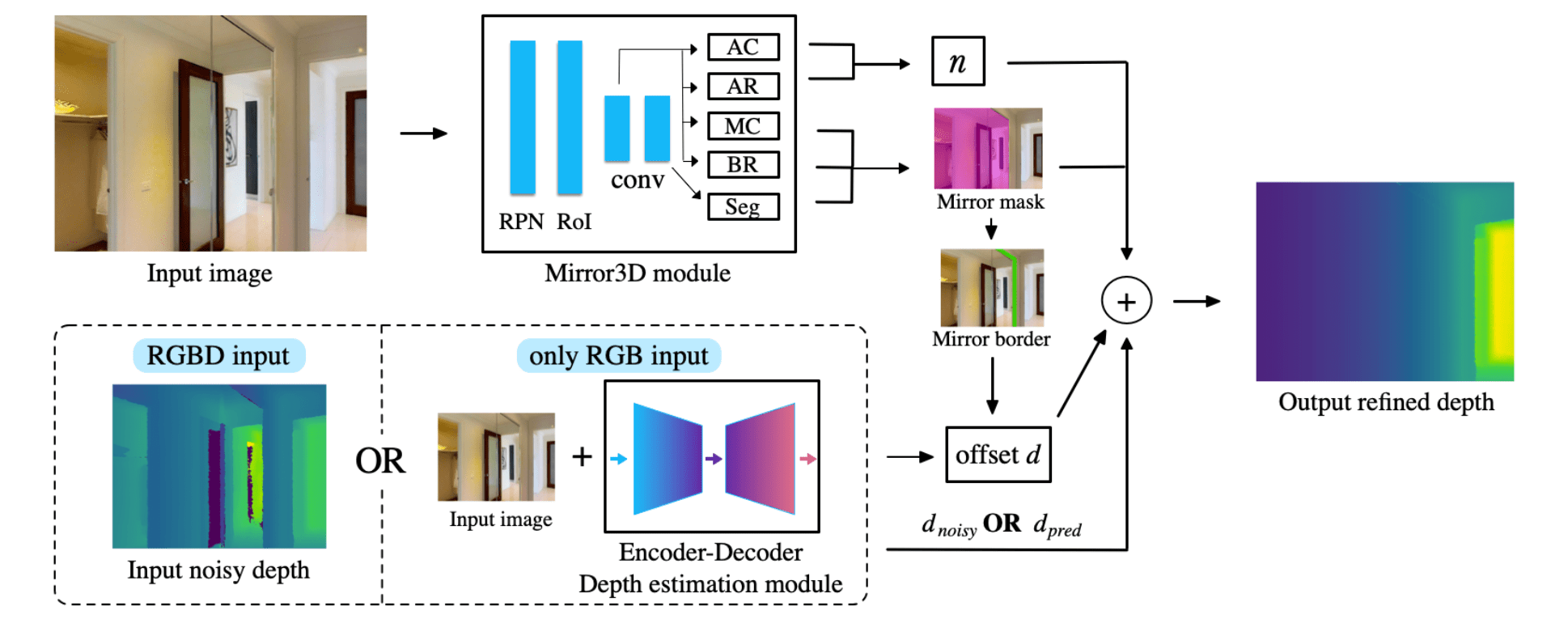
Jiaqi Tan, Weijie (Lewis) Lin, Angel X. Chang, Manolis Savva
In CVPR (2021)
[
![]() Paper
]
Paper
]
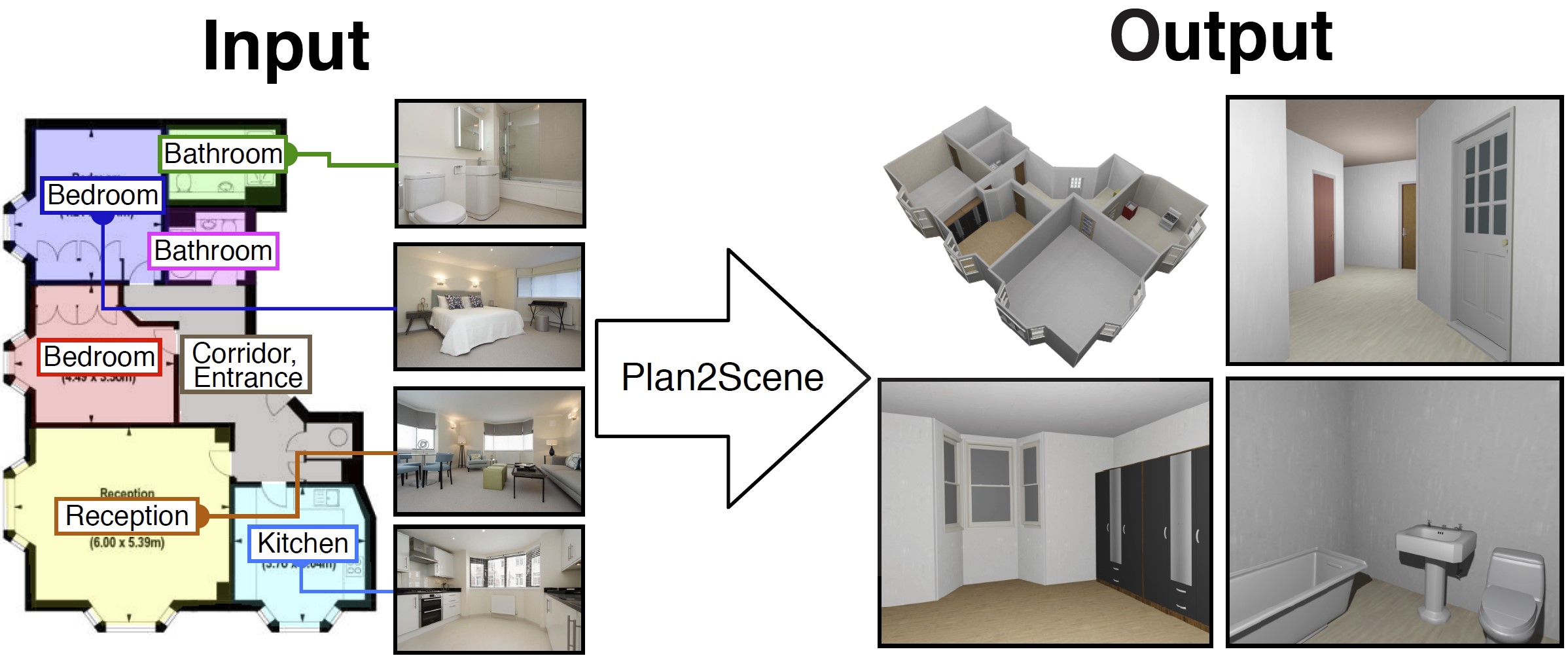
Madhawa Vidanapathirana, Qirui Wu, Yasutaka Furukawa, Angel Chang, and Manolis Savva
In CVPR (2021)
[
![]() Paper
]
Paper
]
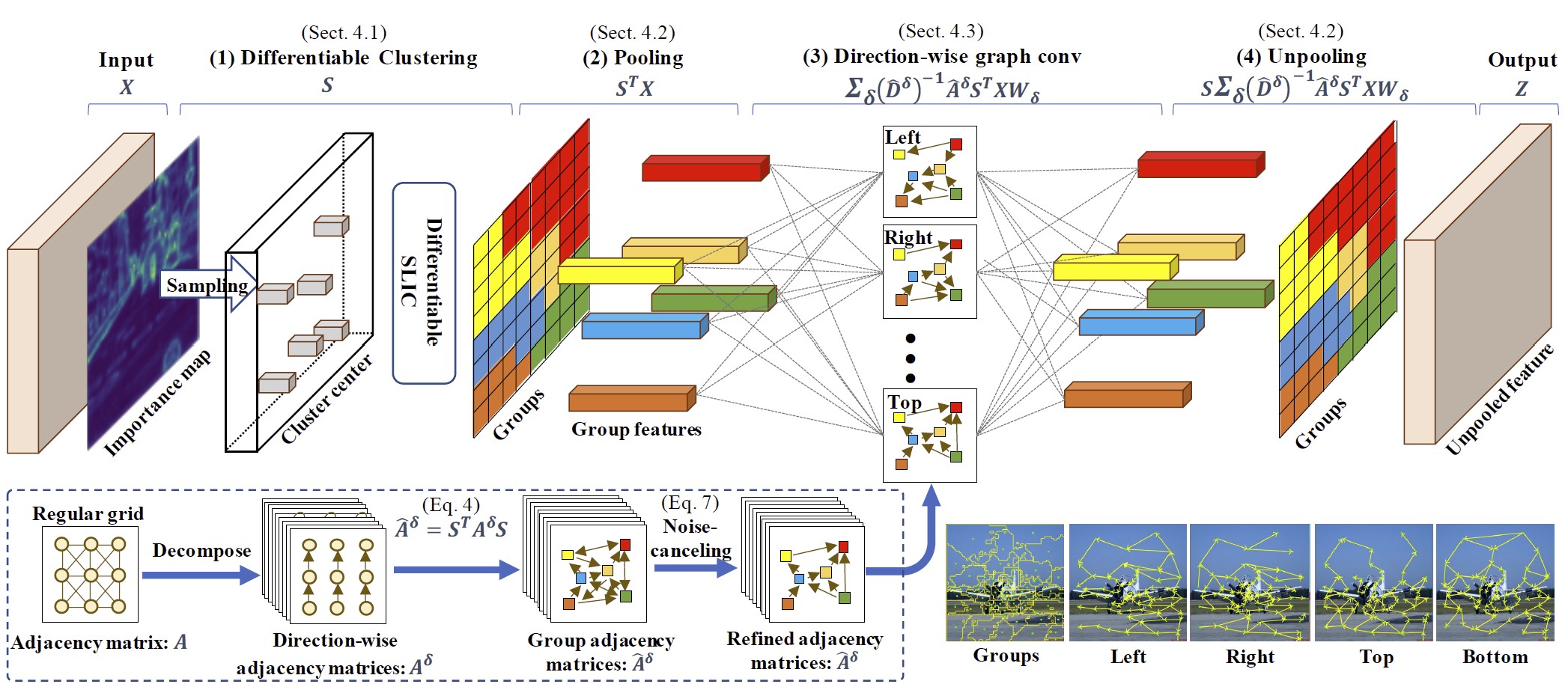
Ryuhei Hamaguchi, Yasutaka Furukawa, Masaki Onishi, and Ken Sakurada
In CVPR (2021)
[
![]() Paper
]
Paper
]
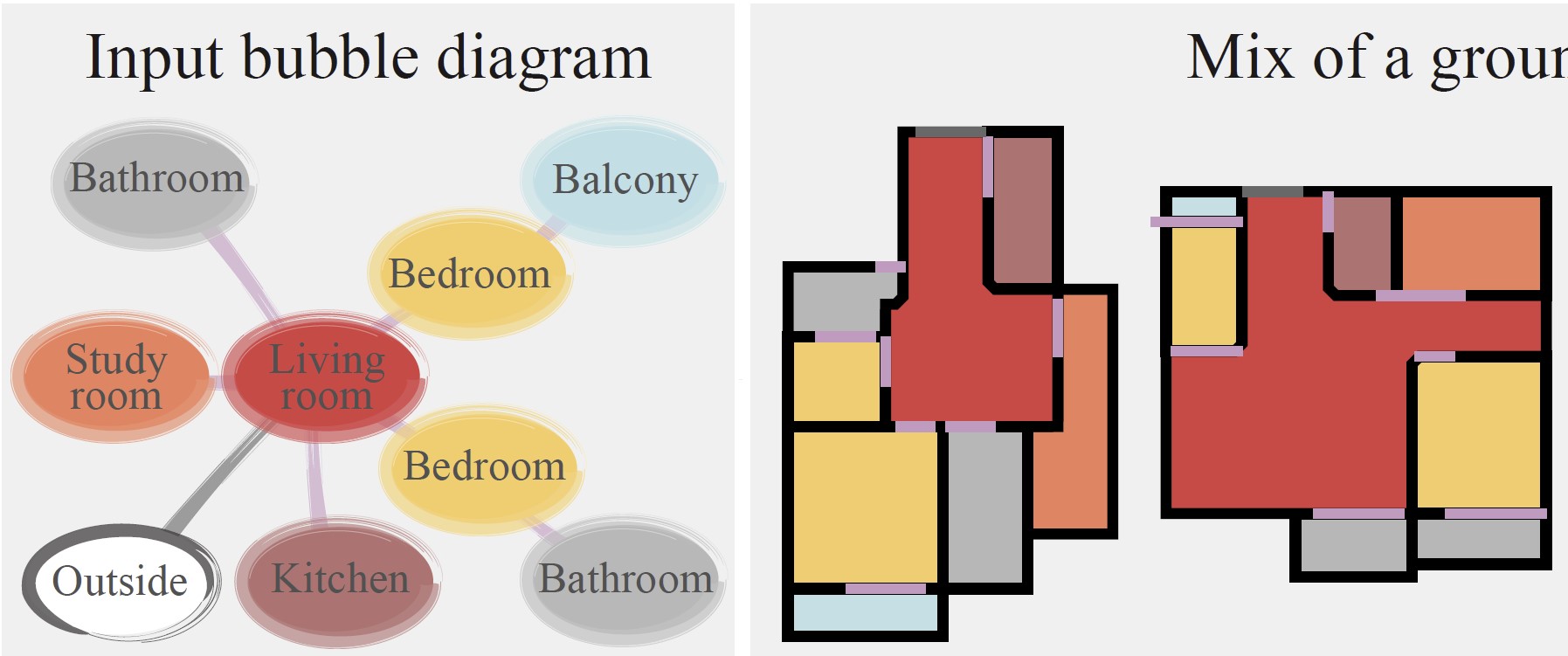
Nelson Nauata, Sepidehsadat Hosseini, Kai-Hung Chang, Hang Chu, Chin-Yi Cheng, and Yasutaka Furukawa
In CVPR (2021)
[
![]() Paper
]
Paper
]

Yiming Qian, Hao Zhang, and Yasutaka Furukawa
In CVPR (2021)
[
![]() Paper
]
Paper
]
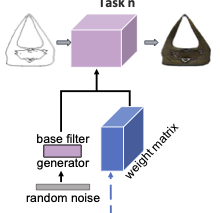
Mengyao Zhai, Lei Chen, and Greg Mori
In CVPR (2021)
[
![]() Paper
]
Paper
]
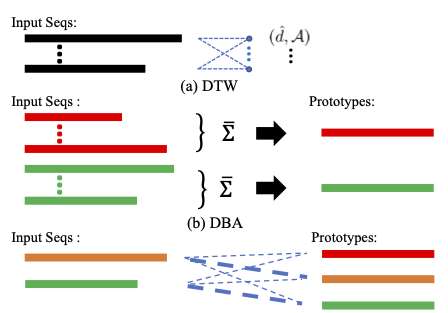
Xiaobin Chang, Frederick Tung, and Greg Mori
In CVPR (2021)
[
![]() Paper
]
Paper
]

S. Mahdi H. Miangoleh, Sebastian Dille, Long Mai, Sylvain Paris, Yagiz Aksoy
In CVPR (2021)
[
![]() Paper
]
Paper
]
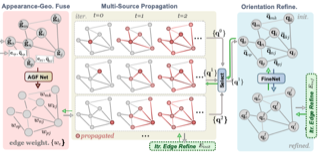
Luwei Yang, Heng Li, Jamal Rahim, Zhaopeng Cui, Ping Tan
In CVPR (2021)
[
![]() Paper
]
Paper
]
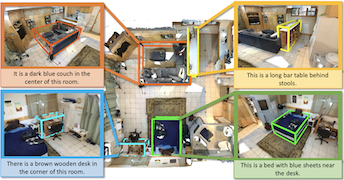
Dave Zhenyu Chen, Angel X. Chang, Matthias Nießner
In ECCV (2020)
This paper introduce the task of 3D object localization in RGB-D scans using natural language descriptions. As input, we assume a point cloud of a scanned 3D scene along with a free-form description of a specified target object. To address this task, we propose ScanRefer, learning a fused descriptor from 3D object proposals and encoded sentence embeddings. This fused descriptor correlates language expressions with geometric features, enabling regression of the 3D bounding box of a target object. We also introduce the ScanRefer dataset, containing 51,583 descriptions of 11,046 objects from 800 ScanNet scenes. ScanRefer is the first large-scale effort to perform object localization via natural language expression directly in 3D.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yiming Qian and Yasutaka Furukawa
In ECCV (2020)
This paper proposes a novel single-image piecewise planar reconstruction technique that infers and enforces inter-plane relationships. Our approach takes a planar reconstruction result from an existing system, then utilizes convolutional neural network (CNN) to (1) classify if two planes are orthogonal or parallel; and 2) infer if two planes are touching and, if so, where in the image. We formulate an optimization problem to refine plane parameters and employ a message passing neural network to refine plane segmentation masks by enforcing the inter-plane relations. Our qualitative and quantitative evaluations demonstrate the effectiveness of the proposed approach in terms of plane parameters and segmentation accuracy.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
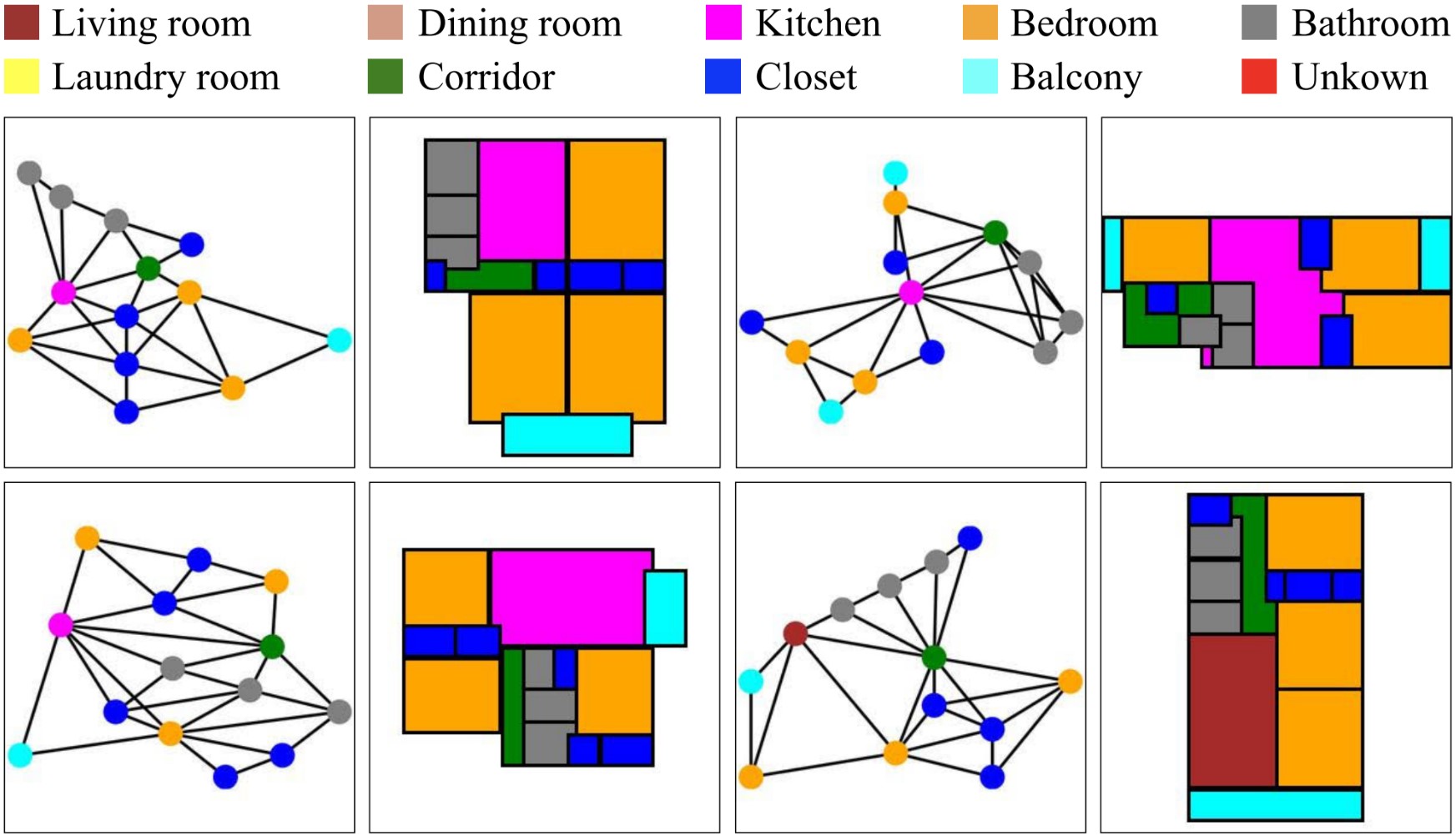
Nelson Nauata, Kai-Hung Chang, Chin-Yi Cheng, Greg Mori, Yasutaka Furukawa
In ECCV (oral presentation) (2020)
This paper proposes a novel graph-constrained generative adversarial network, whose generator and discriminator are built upon relational architecture. The main idea is to encode the constraint into the graph structure of its relational networks. We have demonstrated the proposed architecture for a new house layout generation problem, whose task is to take an architectural constraint as a graph (i.e., the number and types of rooms with their spatial adjacency) and produce a set of axis-aligned bounding boxes of rooms. We measure the quality of generated house layouts with the three metrics: the realism, the diversity, and the compatibility with the input graph constraint. Our qualitative and quantitative evaluations over 117,000 real floorplan images demonstrate that the proposed approach outperforms existing methods and baselines. We will publicly share all our code and data.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Nelson Nauata, Yasutaka Furukawa
In ECCV (2020)
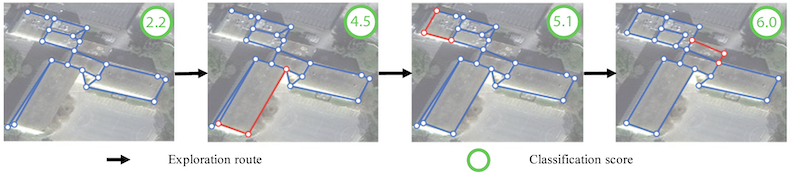
This paper tackles a 2D architecture vectorization problem, whose task is to infer an outdoor building architecture as a 2D planar graph from a single RGB image. We provide a new benchmark with ground-truth annotations for 2,001 complex buildings across the cities of Atlanta, Paris, and Las Vegas. We also propose a novel algorithm utilizing 1) convolutional neural networks (CNNs) that detects geometric primitives and infers their relationships and 2) an integer programming (IP) that assembles the information into a 2D planar graph. While being a trivial task for human vision, the inference of a graph structure with an arbitrary topology is still an open problem for computer vision. Qualitative and quantitative evaluations demonstrate that our algorithm makes significant improvements over the current state-of-the-art, towards an intelligent system at the level of human perception. We will share code and data.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
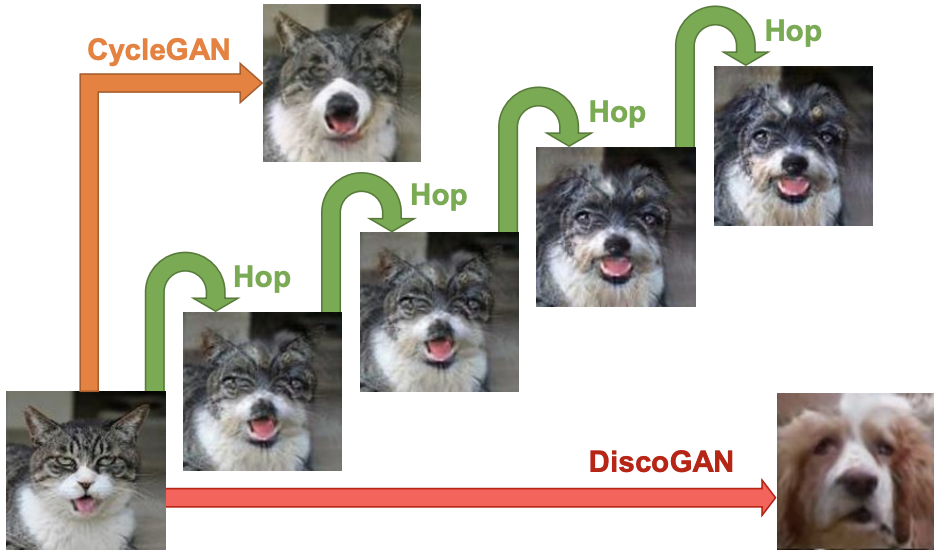
Wallace Lira, Johannes Merz, Daniel Ritchie, Daniel Cohen-Or, and Hao Zhang
In ECCV (2020)
We introduce GANhopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two input domains. Our network is trained on unpaired images from the two domains only, without any in-between images. All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discriminator, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Jiongchao Jin, Akshay Gadi Patil, and Hao Zhang
In ECCV (2020)
We advocate the use of differential visual shape metrics to train deep neural networks for 3D reconstruction. We introduce such a metric which compares two 3D shapes by measuring visual, image-space differences between multiview images differentiably rendered from the shapes. Furthermore, we develop a differentiable image-space distance based on mean-squared errors defined over HardNet features computed from probabilistic keypoint maps of the compared images. Our differential visual shape metric can be easily plugged into various reconstruction networks, replacing the object-space distortion measures, such as Chamfer or Earth Mover distances, so as to optimize the network weights to produce reconstruction results with better structural fidelity and visual quality.
[
![]() Paper
]
Paper
]

Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas Guibas, Hao Su
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 11097-11107). (2020)
Building home assistant robots has long been a pursuit for vision and robotics researchers. To achieve this task, a simulated environment with physically realistic simulation, sufficient articulated objects, and transferability to the real robot is indispensable. Existing environments achieve these requirements for robotics simulation with different levels of simplification and focus. We take one step further in constructing an environment that supports household tasks for training robot learning algorithm. Our work, SAPIEN, is a realistic and physics-rich simulated environment that hosts a large-scale set for articulated objects. Our SAPIEN enables various robotic vision and interaction tasks that require detailed part-level understanding.We evaluate stateof-the-art vision algorithms for part detection and motion attribute recognition as well as demonstrate robotic interaction tasks using heuristic approaches and reinforcement learning algorithms. We hope that our SAPIEN can open a lot of research directions yet to be explored, including learning cognition through interaction, part motion discovery, and construction of robotics-ready simulated game environment.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
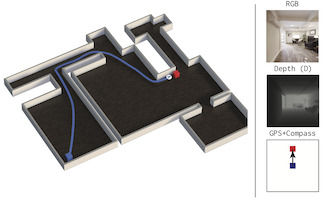
Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, Dhruv Batra
In International Conference on Learning Representations (ICLR), 2020 (2020)
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever ‘stale’), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim (Savva et al., 2019), DD-PPO exhibits near-linear scaling – achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) – over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs. This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially ‘solves’ the task – near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks – the analog of ‘ImageNet pre-training + task-specific fine-tuning’ for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models and code are publicly available).
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Abhishek Kadian, Joanne Truong, Aaron Gokaslan, Alexander Clegg, Erik Wijmans, Stefan Lee, Manolis Savva, Sonia Chernova, Dhruv Batra
In Robotics and Automation Letters (RA-L) & IROS (2020)
Does progress in simulation translate to progress in robotics? Specifically, if method A outperforms method B in simulation, how likely is the trend to hold in reality on a robot? We examine this question for embodied (PointGoal) navigation – developing engineering tools and a research paradigm for evaluating a simulator by its sim2real predictivity, revealing surprising findings about prior work. First, we develop Habitat-PyRobot Bridge (HaPy), a library for seamless execution of identical code on a simulated agent and a physical robot. Habitat-to-Locobot transfer with HaPy involves just one line change in a config parameter, essentially treating reality as just another simulator! Second, we investigate sim2real predictivity of HabitatSim [1] for PointGoal navigation. We 3D-scan a physical lab space to create a virtualized replica, and run parallel tests of 9 different models in reality and simulation. We present a new metric called Sim-vs-Real Correlation Coefficient (SRCC) to quantify sim2real predictivity. Our analysis reveals several important findings. We find that SRCC for Habitat as used for the CVPR19 challenge is low (0.18 for the success metric), which suggests that performance improvements for this simulator-based challenge would not transfer well to a physical robot. We find that this gap is largely due to AI agents learning to ‘cheat’ by exploiting simulator imperfections – specifically, the way Habitat allows for ‘sliding’ along walls on collision. Essentially, the virtual robot is capable of cutting corners, leading to unrealistic shortcuts through parts of non-navigable space. Naturally, such exploits do not work in the real world where the robot stops on contact with walls. Our experiments show that it is possible to optimize simulation parameters to enable robots trained in imperfect simulators to generalize learned skills to reality (e.g. improving SRCCSucc from 0.18 to 0.844).
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Changan Chen, Sha Hu, Payam Nikdel, Greg Mori, Manolis Savva
In International Conference on Intelligent Robots and Systems (IROS) (2020)
We present a relational graph learning approach for robotic crowd navigation using model-based deep reinforcement learning that plans actions by looking into the future. Our approach reasons about the relations between all agents based on their latent features and uses a Graph Convolutional Network to encode higher-order interactions in each agent’s state representation, which is subsequently leveraged for state prediction and value estimation. The ability to predict human motion allows us to perform multi-step lookahead planning, taking into account the temporal evolution of human crowds. We evaluate our approach against a state-of-the-art baseline for crowd navigation and ablations of our model to demonstrate that navigation with our approach is more efficient, results in fewer collisions, and avoids failure cases involving oscillatory and freezing behaviors.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
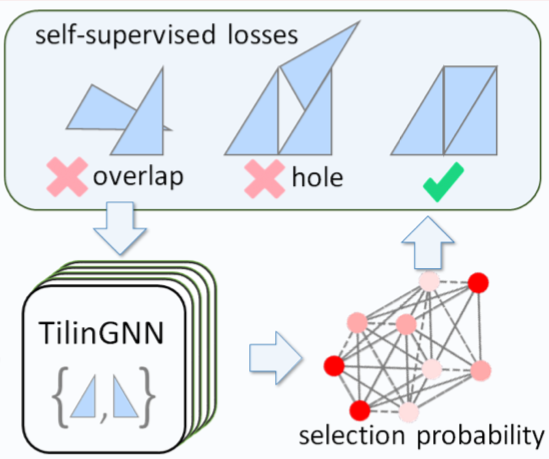
Hao Xu, Ka Hei Hui, Chi-Wing Fu, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), Vol. 39, No. 4, 2020 (2020)
We introduce the first neural optimization framework to solve a classical instance of the tiling problem. Namely, we seek a non-periodic tiling of an arbitrary 2D shape using one or more types of tiles: the tiles maximally fill the shape’s interior without overlaps or holes. To start, we reformulate tiling as a graph problem by modeling candidate tile locations in the target shape as graph nodes and connectivity between tile locations as edges. We build a graph convolutional neural network, coined TilinGNN, to progressively propagate and aggregate features over graph edges and predict tile placements. Our network is self-supervised and trained by maximizing the tiling coverage on target shapes, while avoiding overlaps and holes between the tiles. After training, TilinGNN has a running time that is roughly linear to the number of candidate tile locations, significantly outperforming traditional combinatorial search.
[
![]() Paper
]
Paper
]
Ruizhen Hu, Zeyu Huang, Yuhan Tang, Oliver van Kaick, Hao Zhang, and Hui Huang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), Vol. 39, No. 4, 2020 (2020)
We introduce a learning framework for automated floorplan generation which combines generative modeling using deep neural networks and user-in-the-loop designs to enable human users to provide sparse design constraints. Such constraints are represented by a layout graph. The core component of our learning framework is a deep neural network, Graph2Plan, which is trained on RPLAN, a large-scale dataset consisting of 80K annotated, human-designed floorplans. The network converts a layout graph, along with a building boundary, into a floorplan that fulfills both the layout and boundary constraints.
[
![]() Paper
]
Paper
]
Yanran Guan, Han Liu, Kun Liu, Kangxue Yin, Ruizhen Hu, Oliver van Kaick, Yan Zhang, Ersin Yumer, Nathan Carr, Radomir Mech, and Hao Zhang
In IEEE Trans. on Visualization and Computer Graphics (TVCG), major revision, 2020 (2020)
We introduce a modeling tool which can evolve a set of 3D objects in a functionality-aware manner. Our goal is for the evolution to generate large and diverse sets of plausible 3D objects for data augmentation, constrained modeling, as well as open-ended exploration to possibly inspire new designs. Starting with an initial population of 3D objects belonging to one or more functional categories, we evolve the shapes through part re-combination to produce generations of hybrids or crossbreeds between parents from the heterogeneous shape collection …
[
![]() Paper
]
Paper
]
Zhiqin Chen, Andrea Tagliasacchi, and Hao Zhang
In CVPR (oral presentation), 2020. Best Student Paper Award. (2020)
Polygonal meshes are ubiquitous in the digital 3D domain, yet they have only played a minor role in the deep learning revolution. Leading methods for learning generative models of shapes rely on implicit functions, and generate meshes only after expensive iso-surfacing routines. To overcome these challenges, we are inspired by a classical spatial data structure from computer graphics, Binary Space Partitioning (BSP), to facilitate 3D learning. The core ingredient of BSP is an operation for recursive subdivision of space to obtain convex sets. By exploiting this property, we devise BSP-Net, a network that learns to represent a 3D shape via convex decomposition. Importantly, BSP-Net is unsupervised since no convex shape decompositions are needed for training. The network is trained to reconstruct a shape using a set of convexes obtained from a BSP-tree built on a set of planes. The convexes inferred by BSP-Net can be easily extracted to form a polygon mesh, without any need for iso-surfacing. The generated meshes are compact (i.e., low-poly) and well suited to represent sharp geometry; they are guaranteed to be watertight and can be easily parameterized. We also show that the reconstruction quality by BSP-Net is competitive with state-of-the-art methods while using much fewer primitives.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Nelson Nauata * , Fuyang Zhang * , and Yasutaka Furukawa (* indicates equal contribution)
In CVPR 2020 (2020)
This paper proposes a novel message passing neural (MPN) architecture Conv-MPN, which reconstructs an outdoor building as a planar graph from a single RGB image. Conv-MPN is specifically designed for cases where nodes of a graph have explicit spatial embedding. In our problem, nodes correspond to building edges in an image. Conv-MPN is different from MPN in that 1) the feature associated with a node is represented as a feature volume instead of a 1D vector; and 2) convolutions encode messages instead of fully connected layers. Conv-MPN learns to select a true subset of nodes (i.e., building edges) to reconstruct a building planar graph. Our qualitative and quantitative evaluations over 2,000 buildings show that Conv-MPN makes significant improvements over the existing fully neural solutions. We believe that the paper has a potential to open a new line of graph neural network research for structured geometry reconstruction.
[
![]() Paper
|
Paper
|
![]() Bibtex
|
Bibtex
|
![]() Project Page
]
Project Page
]

Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J. Guibas, and Hao Zhang
In CVPR (oral presentation), 2020 (2020)
We introduce AdaSeg, a deep neural network architecture for adaptive co-segmentation of a set of 3D shapes represented as point clouds. Differently from the familiar single-instance segmentation problem, co-segmentation is intrinsically contextual: how a shape is segmented can vary depending on the set it is in. Hence, our network features an adaptive learning module to produce a consistent shape segmentation which adapts to a set.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Rundi Wu, Yixin Zhuang, Kai Xu, Hao Zhang, and Baoquan Chen
In CVPR, 2020 (2020)
We introduce PQ-NET, a deep neural network which represents and generates 3D shapes via sequential part assembly. The input to our network is a 3D shape segmented into parts, where each part is first encoded into a feature representation using a part autoencoder. The core component of PQ-NET is a sequence-to-sequence or Seq2Seq autoencoder which encodes a sequence of part features into a latent vector of fixed size, and the decoder reconstructs the 3D shape, one part at a time, resulting in a sequential assembly. The latent space formed by the Seq2Seq encoder encodes both part structure and fine part geometry. The decoder can be adapted to perform several generative tasks including shape autoencoding, interpolation, novel shape generation, and single-view 3D reconstruction, where the generated shapes are all composed of meaningful parts.
[
![]() Paper
]
Paper
]

Siddhartha Chaudhuri, Daniel Ritchie, Jiajun Wu, Kai Xu, and Hao Zhang
In Computer Graphics Forum (Eurographics STAR), 2020 (2020)
3D models of objects and scenes are critical to many academic disciplines and industrial applications. Of particular interest is the emerging opportunity for 3D graphics to serve artificial intelligence: computer vision systems can benefit from synthetically- generated training data rendered from virtual 3D scenes, and robots can be trained to navigate in and interact with real-world environments by first acquiring skills in simulated ones. One of the most promising ways to achieve this is by learning and applying generative models of 3D content: computer programs that can synthesize new 3D shapes and scenes. To allow users to edit and manipulate the synthesized 3D content to achieve their goals, the generative model should also be structure-aware: it should express 3D shapes and scenes using abstractions that allow manipulation of their high-level structure. This state-of-the- art report surveys historical work and recent progress on learning structure-aware generative models of 3D shapes and scenes.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Kai Wang, Yu-An Lin, Ben Weissmann, Angel X. Chang, Manolis Savva, Daniel Ritchie
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), 38(4), pp.1-15. (2019)
We present a new framework for interior scene synthesis that combines a high-level relation graph representation with spatial prior neural networks. We observe that prior work on scene synthesis is divided into two camps: object-oriented approaches (which reason about the set of objects in a scene and their configurations) and space-oriented approaches (which reason about what objects occupy what regions of space). Our insight is that the object-oriented paradigm excels at high-level planning of how a room should be laid out, while the space-oriented paradigm performs well at instantiating a layout by placing objects in precise spatial configurations. With this in mind, we present PlanIT, a layout-generation framework that divides the problem into two distinct planning and instantiation phases. PlanIT repre- sents the “plan” for a scene via a relation graph, encoding objects as nodes and spatial/semantic relationships between objects as edges. In the planning phase, it uses a deep graph convolutional generative model to synthesize relation graphs. In the instantiation phase, it uses image-based convolutional network modules to guide a search procedure that places objects into the scene in a manner consistent with the graph. By decomposing the problem in this way, PlanIT generates scenes of comparable quality to those generated by prior approaches (as judged by both people and learned classifiers), while also providing the modeling flexibility of the intermediate relationship graph representation. These graphs allow the system to support applications such as scene synthesis from a partial graph provided by a user.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Julian Straub, Thomas Whelan, Lingni Ma, Yufan Chen, Erik Wijmans, Simon Green, Jakob J. Engel, Raul Mur-Artal, Carl Ren, Shobhit Verma, Anton Clarkson, Mingfei Yan, Brian Budge, Yajie Yan, Xiaqing Pan, June Yon, Yuyang Zou, Kimberly Leon, Nigel Carter, Jesus Briales, Tyler Gillingham, Elias Mueggler, Luis Pesqueira, Manolis Savva, Dhruv Batra, Hauke M. Strasdat, Renzo De Nardi, Michael Goesele, Steven Lovegrove, Richard Newcombe
In arXiv:1906.05797 (2019)
We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, highresolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world – for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is ‘Habitatcompatible’, i.e. can be natively used with AI Habitat [24] for training and testing embodied agents.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Manolis Savva, Abhishek Kadian, Oleksandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, Dhruv Batra
In In Proceedings of the IEEE International Conference on Computer Vision (pp. 9339-9347). (2019)
We present Habitat, a platform for research in embodied artificial intelligence (AI). Habitat enables training embodied agents (virtual robots) in highly efficient photorealistic 3D simulation. Specifically, Habitat consists of: (i) Habitat-Sim: a flexible, high-performance 3D simulator with configurable agents, sensors, and generic 3D dataset handling. Habitat-Sim is fast – when rendering a scene from Matterport3D, it achieves several thousand frames per second (fps) running single-threaded, and can reach over 10,000 fps multi-process on a single GPU. (ii) Habitat-API: a modular high-level library for end-toend development of embodied AI algorithms – defining tasks (e.g. navigation, instruction following, question answering), configuring, training, and benchmarking embodied agents. These large-scale engineering contributions enable us to answer scientific questions requiring experiments that were till now impracticable or ‘merely’ impractical. Specifically, in the context of point-goal navigation: (1) we revisit the comparison between learning and SLAM approaches from two recent works [20, 16] and find evidence for the opposite conclusion – that learning outperforms SLAM if scaled to an order of magnitude more experience than previous investigations, and (2) we conduct the first cross-dataset generalization experiments {train, test} × {Matterport3D, Gibson} for multiple sensors {blind, RGB, RGBD, D} and find that only agents with depth (D) sensors generalize across datasets. We hope that our open-source platform and these findings will advance research in embodied AI.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Yifei Shi, Angel X. Chang, Zhelun Wu, Manolis Savva, Kai Xu
In In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1771-1780). (2019)
Indoor scenes exhibit rich hierarchical structure in 3D object layouts. Many tasks in 3D scene understanding can benefit from reasoning jointly about the hierarchical context of a scene, and the identities of objects. We present a variational denoising recursive autoencoder (VDRAE) that generates and iteratively refines a hierarchical representation of 3D object layouts, interleaving bottom-up encoding for context aggregation and top-down decoding for propagation. We train our VDRAE on large-scale 3D scene datasets to predict both instance-level segmentations and a 3D object detections from an over-segmentation of an input point cloud. We show that our VDRAE improves object detection performance on real-world 3D point cloud datasets compared to baselines from prior work.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
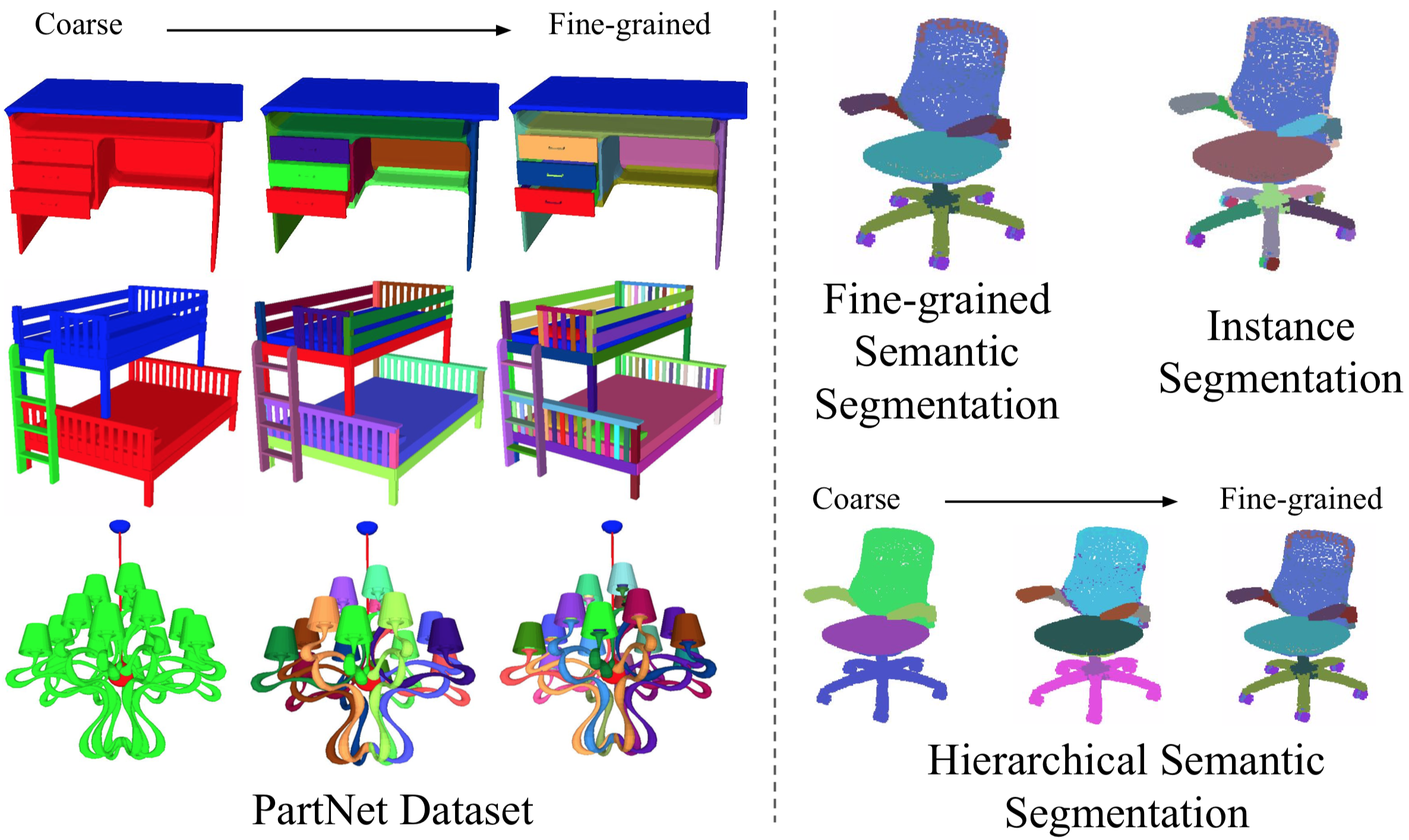
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas Guibas, Hao Su
In In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 909-918). (2019)
We present PartNet: a consistent, large-scale dataset of 3D objects annotated with fine-grained, instance-level, and hierarchical 3D part information. Our dataset consists of 573,585 part instances over 26,671 3D models covering 24 object categories. This dataset enables and serves as a catalyst for many tasks such as shape analysis, dynamic 3D scene modeling and simulation, affordance analysis, and others. Using our dataset, we establish three benchmarking tasks for evaluating 3D part recognition: fine-grained semantic segmentation, hierarchical semantic segmentation, and instance segmentation. We benchmark four state-ofthe-art 3D deep learning algorithms for fine-grained semantic segmentation and three baseline methods for hierarchical semantic segmentation. We also propose a novel method for part instance segmentation and demonstrate its superior performance over existing methods.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
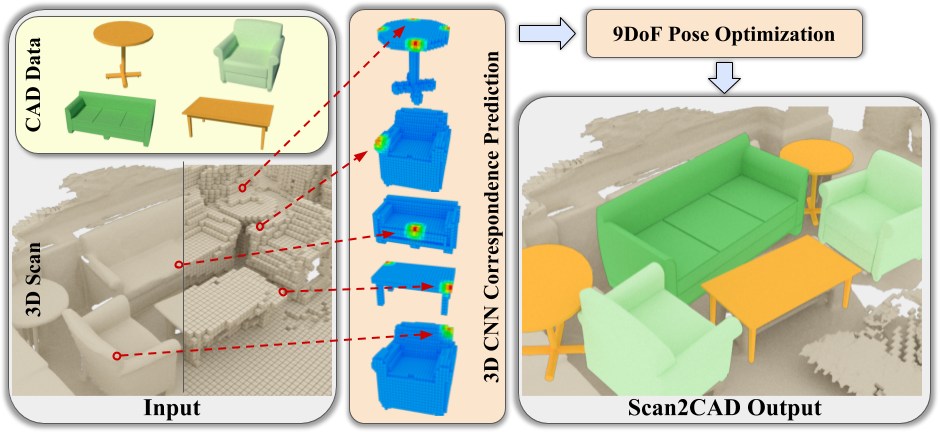
Armen Avetisyan, Manuel Dahnert, Angela Dai, Manolis Savva, Angel X. Chang, Matthias Nießner
In In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2614-2623). (2019)
We present Scan2CAD1 , a novel data-driven method that learns to align clean 3D CAD models from a shape database to the noisy and incomplete geometry of an RGBD scan. For a 3D reconstruction of an indoor scene, our method takes as input a set of CAD models, and predicts a 9DoF pose that aligns each model to the underlying scan geometry. To tackle this problem, we create a new scanto-CAD alignment dataset based on 1506 ScanNet scans with 97607 annotated keypoint pairs between 14225 CAD models from ShapeNet and their counterpart objects in the scans. Our method selects a set of representative keypoints in a 3D scan for which we find correspondences to the CAD geometry. To this end, we design a novel 3D CNN architecture to learn a joint embedding between real and synthetic objects, and thus predict a correspondence heatmaps. Based on these correspondence heatmaps, we formulate a variational energy minimization that aligns a given set of CAD models to the reconstruction. We evaluate our approach on our newly introduced Scan2CAD benchmark where we outperform both handcrafted feature descriptor as well as state-of-the-art CNN based methods by 21.39%.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Justin Dieter, Tian Wang, Gabor Angeli, Angel X. Chang, Arun Tejasvi Chaganty
In In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL) (pp. 393-403). (2019)
Reflective listening—demonstrating that you have heard your conversational partner—is key to effective communication. Expert human communicators often mimic and rephrase their conversational partner, e.g., when responding to sentimental stories or to questions they don’t know the answer to. We introduce a new task and an associated dataset wherein dialogue agents similarly mimic and rephrase a user’s request to communicate sympathy (I’m sorry to hear that) or lack of knowledge (I do not know that). We study what makes a rephrasal response good against a set of qualitative metrics. We then evaluate three models for generating responses: a syntax-aware rulebased system, a seq2seq LSTM neural models with attention (S2SA), and the same neural model augmented with a copy mechanism (S2SA+C). In a human evaluation, we find that S2SA+C and the rule-based system are comparable and approach human-generated response quality. In addition, experiences with a live deployment of S2SA+C in a customer support setting suggest that this generation task is a practical contribution to real world conversational agents.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Kangxue Yin, Zhiqin Chen, Hui Huang, Daniel Cohen-Or, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 38, No. 6, Article 198, 2019 (2019)
We introduce LOGAN, a deep neural network aimed at learning general-purpose shape transforms from unpaired domains. The network is trained on two sets of shapes, e.g., tables and chairs, while there is neither a pairing between shapes from the domains as supervision nor any point-wise correspondence between any shapes. Once trained, LOGAN takes a shape from one domain and transforms it into the other. Our network consists of an autoencoder to encode shapes from the two input domains into a common latent space, where the latent codes concatenate multi-scale shape features, resulting in an overcomplete representation. The translator is based on a latent generative adversarial network (GAN), where an adversarial loss enforces cross-domain translation while a feature preservation loss ensures that the right shape features are preserved for a natural shape transform.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Lin Gao, Jie Yang, Tong Wu, Yu-Jie Yuan, Hongbo Fu, Yu-Kun Lai, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 38, No. 6, Article 243, 2019 (2019)
We introduce SDM-NET, a deep generative neural network which produces structured deformable meshes. Specifically, the network is trained to generate a spatial arrangement of closed, deformable mesh parts, which respect the global part structure of a shape collection, e.g., chairs, airplanes, etc. Our key observation is that while the overall structure of a 3D shape can be complex, the shape can usually be decomposed into a set of parts, each homeomorphic to a box, and the finer-scale geometry of the part can be recovered by deforming the box. The architecture of SDM-NET is that of a two-level variational autoencoder (VAE). At the part level, a PartVAE learns a deformable model of part geometries. At the structural level, we train a Structured Parts VAE (SP-VAE), which jointly learns the part structure of a shape collection and the part geometries, ensuring a coherence between global shape structure and surface details.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
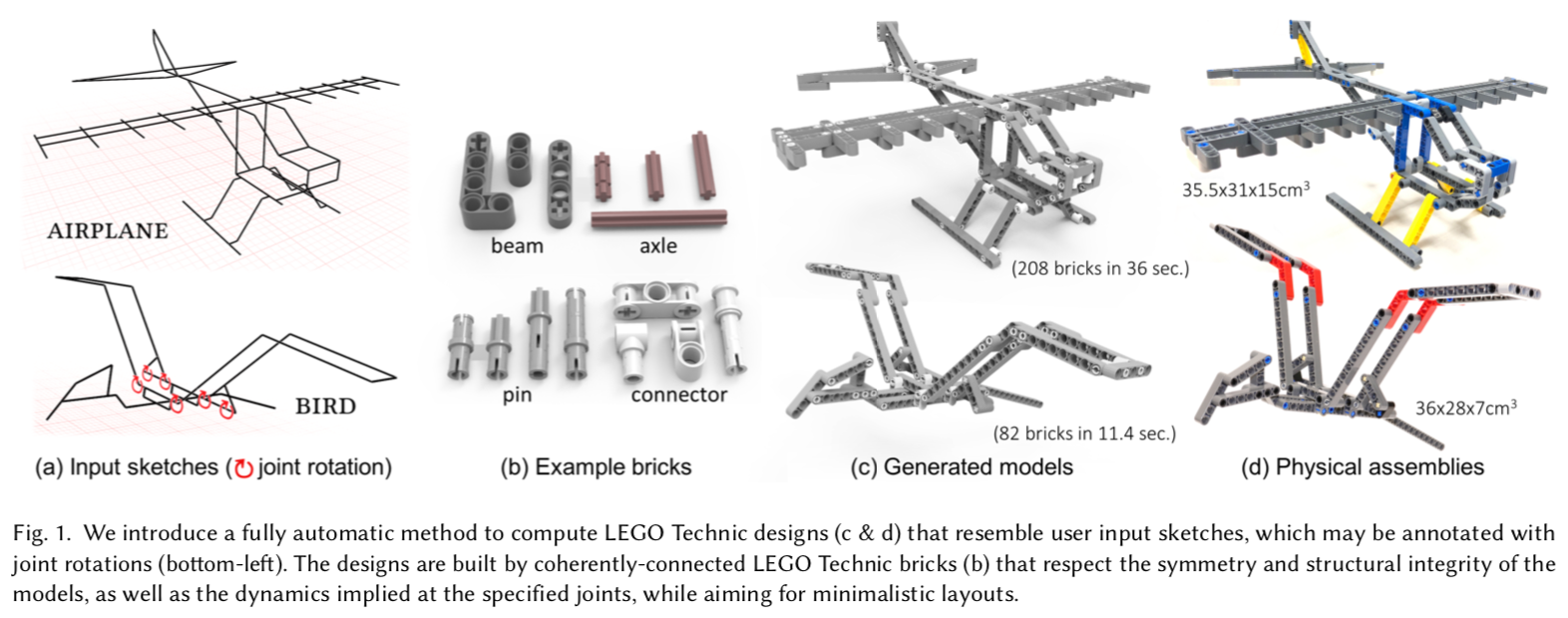
Hao Xu, Ka Hei Hui, Chi-Wing Fu, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 38, No. 6, Article 196, 2019 (2019)
We introduce a method to automatically compute LEGO Technic models from user input sketches, optionally with motion annotations. The generated models resemble the input sketches with coherently-connected bricks and simple layouts, while respecting the intended symmetry and mechanical properties expressed in the inputs. This complex computational assembly problem involves an immense search space, and a much richer brick set and connection mechanisms than regular LEGO. To address it, we first comprehensively model the brick properties and connection mechanisms, then formulate the construction requirements into an objective function, accounting for faithfulness to input sketch, model simplicity, and structural integrity. Next, we model the problem as a sketch cover, where we iteratively refine a random initial layout to cover the input sketch, while guided by the objective. At last, we provide a working system to analyze the balance, stress, and assemblability of the generated model.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
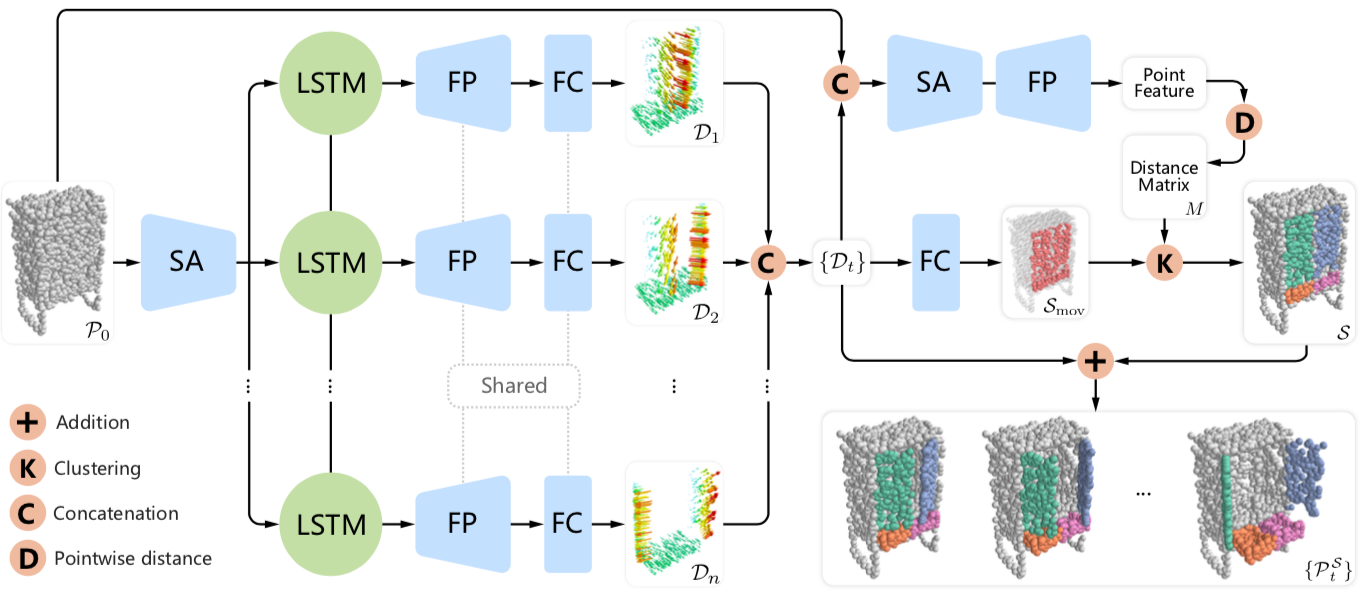
Zhihao Yan, Ruizhen Hu, Xingguang Yan, Luanmin Chen, Oliver van Kaick, Hao Zhang, and Hui Huang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 38, No. 6, Article 240, 2019 (2019)
We introduce RPM-Net, a deep learning-based approach which simultaneously infers movable parts and hallucinates their motions from a single, un-segmented, and possibly partial, 3D point cloud shape. RPM-Net is a novel Recurrent Neural Network (RNN), composed of an encoder-decoder pair with interleaved Long Short-Term Memory (LSTM) components, which together predict a temporal sequence of point-wise displacements for the input shape. At the same time, the displacements allow the network to learn moveable parts, resulting in a motion-based shape segmentation. Recursive applications of RPM-Net on the obtained parts can predict finer-level part motions, resulting in a hierarchical object segmentation. Furthermore, we develop a separate network to estimate part mobilities, e.g., per part motion parameters, from the segmented motion sequence.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhiqin Chen, Kangxue Yin, Matt Fisher, Siddhartha Chaudhuri, and Hao Zhang
In ICCV 2019 (2019)
We treat shape co-segmentation as a representation learning problem and introduce BAE-NET, a branched autoencoder network, for the task. The unsupervised BAE-NET is trained with all shapes in an input collection using a shape reconstruction loss, without ground-truth segmentations. Specifically, the network takes an input shape and encodes it using a convolutional neural network, whereas the decoder concatenates the resulting feature code with a point coordinate and outputs a value indicating whether the point is inside/outside the shape. Importantly, the decoder is branched: each branch learns a compact representation for one commonly recurring part of the shape collection, e.g., airplane wings. By complementing the shape reconstruction loss with a label loss, BAE-NET is easily tuned for one-shot learning.
[
![]() Paper
]
Paper
]
Nadav Schor, Oren Katzier, Hao Zhang, and Daniel Cohen-Or
In ICCV 2019 (2019)
Data-driven generative modeling has made remarkable progress by leveraging the power of deep neural networks. A reoccurring challenge is how to sample a rich variety of data from the entire target distribution, rather than only from the distribution of the training data. In other words, we would like the generative model to go beyond the observed training samples and learn to also generate “unseen” data. In our work, we present a generative neural network for shapes that is based on a part-based prior, where the key idea is for the network to synthesize shapes by varying both the shape parts and their compositions.
[
![]() Paper
]
Paper
]

Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Li Yi, Leonidas J. Guibas, and Hao Zhang
In arXiv (2019)
We introduce CoSegNet, a deep neural network architecture for co-segmentation of a set of 3D shapes represented as point clouds. CoSegNet takes as input a set of unsegmented shapes, proposes per-shape parts, and then jointly optimizes the part labelings across the set subjected to a novel group consistency loss expressed via matrix rank estimates. The proposals are refined in each iteration by an auxiliary network that acts as a weak regularizing prior, pre-trained to denoise noisy, unlabeled parts from a large collection of segmented 3D shapes, where the part compositions within the same object category can be highly inconsistent. The output is a consistent part labeling for the input set, with each shape segmented into up to K (a user-specified hyperparameter) parts.
[
![]() Paper
]
Paper
]

Zhiqin Chen and Hao Zhang
In CVPR 2019 (2019)
We advocate the use of implicit fields for learning generative models of shapes and introduce an implicit field decoder for shape generation, aimed at improving the visual quality of the generated shapes. An implicit field assigns a value to each point in 3D space, so that a shape can be extracted as an iso-surface. Our implicit field decoder is trained to perform this assignment by means of a binary classifier. Specifically, it takes a point coordinate, along with a feature vector encoding a shape, and outputs a value which indicates whether the point is outside the shape or not …
[
![]() Paper
|
Paper
|
![]() Bibtex
|
Bibtex
|
![]() Project Page
]
Project Page
]
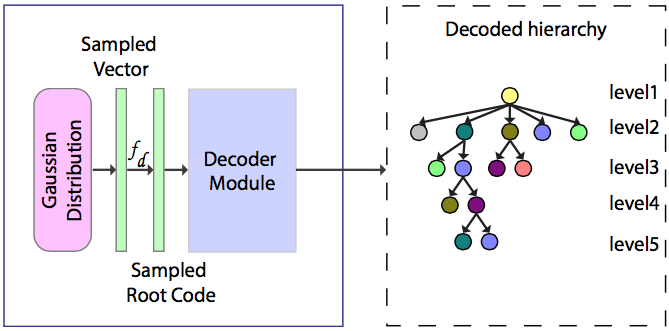
Manyi Li, Akshay Gadi Patil, Kai Xu, Siddhartha Chaudhuri, Owais Khan, Ariel Shamir, Changhe Tu, Baoquan Chen, Daniel Cohen-Or, and Hao Zhang
In ACM Transactions on Graphics, to appear and be presented at SIGGRAPH 2019 (2019)
We present a generative neural network which enables us to generate plausible 3D indoor scenes in large quantities and varieties, easily and highly efficiently. Our key observation is that indoor scene structures are inherently hierarchical. Hence, our network is not convolutional; it is a recursive neural network or RvNN. Using a dataset of annotated scene hierarchies, we train a variational recursive autoencoder, or RvNN-VAE, which performs scene object grouping during its encoding phase and scene generation during decoding.

Yuan Gan, Yan Zhang, and Hao Zhang
In Proc. of Graphics Interface, 2019 (2019)
We introduce the use of qualitative analysis and active learning to photo album construction. Given a heterogeneous collection of pho- tos, we organize them into a hierarchical categorization tree (C-tree) based on qualitative analysis using quartets instead of relying on conventional, quantitative image similarity metrics. The main moti- vation is that in a heterogeneous collection, quantitative distances may become unreliable between dissimilar data and there is unlikely a single metric that is well applicable to all data.
[
![]() Paper
]
Paper
]

Pengfei Xu, Jiangqiang Ding, Hao Zhang, and Hui Huang
In Computational Visual Media (CVM), 2019 (2019)
We present a novel method to produce discernible image mosaics, with relatively large image tiles replaced by images drawn from a database, to resemble a target image. Since visual edges strongly support content perception, we compose our mosaic via edge-aware photo retrieval to best preserve visual edges in the target image. Moreover, unlike most previous works which apply a pre-determined partition to an input image, our image mosaics are composed by adaptive tiles, whose sizes are determined based on the available images and an objective of maximizing resemblance to the target.
[
![]() Bibtex
|
Bibtex
|
![]() Project Page
]
Project Page
]
Zili Yi, Zhiqin Chen, Hao Cai, Xin Huang, Minglun Gong, and Hao Zhang
In arXiv (2018)
We introduce BranchGAN, a novel training method that enables unconditioned generative adversarial networks (GANs) to learn image manifolds at multiple scales. The key novel feature of BranchGAN is that it is trained in multiple branches, progressively covering both the breadth and depth of the network, as resolutions of the training images increase to reveal finer-scale features. Specifically, each noise vector, as input to the generator network, is explicitly split into several sub-vectors, each corresponding to, and is trained to learn, image representations at a particular scale. During training, we progressively “de-freeze” the sub-vectors, one at a time, as a new set of higher-resolution images is employed for training and more network layers are added.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Chenyang Zhu, Kai Xu, Siddhartha Chaudhuri, Renjiao Yi, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 37, No. 6 (2018)
We introduce SCORES, a recursive neural network for shape composition. Our network takes as input sets of parts from two or more source 3D shapes and a rough initial placement of the parts. It outputs an optimized part structure for the composed shape, leading to high-quality geometry construction. A unique feature of our composition network is that it is not merely learning how to connect parts. Our goal is to produce a coherent and plausible 3D shape, despite large incompatibilities among the input parts. The network may significantly alter the geometry and structure of the input parts and synthesize a novel shape structure based on the inputs, while adding or removing parts to minimize a structure plausibility loss.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Wallace Lira, Chi-Wing Fu, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 37, No. 6 (2018)
We present a fully automatic method that finds a small number of machine fabricable wires with minimal overlap to reproduce a wire sculpture design as a 3D shape abstraction. Importantly, we consider non-planar wires, which can be fabricated by a wire bending machine, to enable efficient construction of complex 3D sculptures that cannot be achieved by previous works. We call our wires Eulerian wires, since they are as Eulerian as possible with small overlap to form the target design together.
[
![]() Project Page
]
Project Page
]

Shuhua Li, Ali Mahdavi-Amiri, Ruizhen Hu, Han Liu, Changqing Zou, Oliver van Kaick, Xiuping Liu, Hui Huang, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 37, No. 6 (2018)
We study a new and elegant instance of geometric dissection of 2D shapes: reversible hinged dissection, which corresponds to a dual transform between two shapes where one of them can be dissected in its interior and then inverted inside-out, with hinges on the shape boundary, to reproduce the other shape, and vice versa. We call such a transform reversible inside-out transform or RIOT. Since it is rare for two shapes to possess even a rough RIOT, let alone an exact one, we develop both a RIOT construction algorithm and a quick filtering mechanism to pick, from a shape collection, potential shape pairs that are likely to possess the transform. Our construction algorithm is fully automatic. It computes an approximate RIOT between two given input 2D shapes, whose boundaries can undergo slight deformations, while the filtering scheme picks good inputs for the construction.
[
![]() Project Page
]
Project Page
]

Rui Ma, Akshay Gadi Patil (co-first author), Matt Fisher, Manyi Li, Soren Pirk, Binh-Son Hua, Sai-Kit Yeung, Xin Tong, Leonidas J. Guibas, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 37, No. 6 (2018)
We introduce a novel framework for using natural language to generate and edit 3D indoor scenes, harnessing scene semantics and text-scene grounding knowledge learned from large annotated 3D scene databases. The advantage of natural language editing interfaces is strongest when performing semantic operations at the sub-scene level, acting on groups of objects. We learn how to manipulate these sub-scenes by analyzing existing 3D scenes. We perform edits by first parsing a natural language command from the user and trans- forming it into a semantic scene graph that is used to retrieve corresponding sub-scenes from the databases that match the command. We then augment this retrieved sub-scene by incorporating other objects that may be implied by the scene context. Finally, a new 3D scene is synthesized by aligning the augmented sub-scene with the user’s current scene, where new objects are spliced into the environment, possibly triggering appropriate adjustments to the existing scene arrangement.
[
![]() Project Page
]
Project Page
]

Xuelin Chen, Honghua Li, Chi-Wing Fu, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia), Vol. 37, No. 6 (2018)
We introduce a computational solution for cost-efficient 3D fabrication using universal building blocks. Our key idea is to employ a set of universal blocks, which can be massively prefabricated at a low cost, to quickly assemble and constitute a significant internal core of the target object, so that only the residual volume need to be 3D printed online. We further improve the fabrication efficiency by decomposing the residual volume into a small number of printing-friendly pyramidal pieces.
[
![]() Project Page
]
Project Page
]

Changqing Zou, Qian Yu, Ruofei Du, Haoran Mo, Yi-Zhe Song, Tao Xiang, Chengyi Gao, Baoquan Chen, and Hao Zhang
In ECCV (2018)
We contribute the first large-scale dataset of scene sketches, SketchyScene, with the goal of advancing research on sketch understanding at both the object and scene level. The dataset is created through a novel and carefully designed crowdsourcing pipeline, enabling users to efficiently generate large quantities realistic and diverse scene sketches. SketchyScene contains more than 29,000 scene-level sketches, 7,000+ pairs of scene templates and photos, and 11,000+ object sketches. All objects in the scene sketches have ground-truth semantic and instance masks. The dataset is also highly scalable and extensible, easily allowing augmenting and/or changing scene composition. We demonstrate the potential impact of SketchyScene by training new computational models for semantic segmentation of scene sketches and showing how the new dataset enables several applications including image retrieval, sketch colorization, editing, and captioning, etc. We will release the complete crowdsourced dataset to the community.
[
![]() Paper
]
Paper
]
Kangxue Yin, Hui Huang, Daniel Cohen-Or, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), Vol. 37, No. 4, Article 152 (2018)
We introduce P2P-NET, a general-purpose deep neural network which learns geometric transformations between point-based shape representations from two domains, e.g., meso-skeletons and surfaces, partial and complete scans, etc. The architecture of the P2P-NET is that of a bi-directional point dis- placement network, which transforms a source point set to a prediction of the target point set with the same cardinality, and vice versa, by applying point-wise displacement vectors learned from data. P2P-NET is trained on paired shapes from the source and target domains, but without relying on point-to-point correspondences between the source and target point sets. The training loss combines two uni-directional geometric losses, each enforc- ing a shape-wise similarity between the predicted and the target point sets, and a cross-regularization term to encourage consistency between displace- ment vectors going in opposite directions.
[
![]() Paper
]
Paper
]
Ruizhen Hu, Zhihao Yan, Jingwen Zhang, Oliver van Kaick, Ariel Shamir, Hao Zhang, and Hui Huang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), Vol. 37, No. 4, Article 151 (2018)
Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to “hallucinate” the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts involving the object. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the object’s functionalities. iSEG-NET separates the interacting objects into different groups according to their interaction types.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Haisen Zhao, Hao Zhang, Shiqing Xin, Yuanmin Deng, Changhe Tu, Wenping Wang, Daniel Cohen-Or, and Baoquan Chen
In ACM Transactions on Graphics (Special Issue of SIGGRAPH), Vol. 37, No. 4, Article 137 (2018)
We present an automatic algorithm for subtractive manufacturing of freeform 3D objects using high-speed CNC machining. Our method decomposes the input object’s surface into a small number of patches each of which is fully accessible and machinable by the CNC machine, in continuous fashion, under a fixed drill-object setup configuration. This is achieved by covering the input surface using a minimum number of accessible regions and then extracting a set of machinable patches from each accessible region. For each patch obtained, we compute a continuous, space-filling, and iso-scallop tool path, in the form of connected Fermat spirals, which conforms to the patch boundary. Furthermore, we develop a novel method to control the spacing of Fermat spirals based on directional surface curvature and adapt the heat method to obtain iso-scallop carving.
[
![]() Paper
]
Paper
]

Kangxue Yin, Hui Huang, Edmond S. L. Ho, Hao Wang, Taku Komura, Daniel Cohen-Or, and Hao Zhang
In IEEE Trans. on Visualization and Computer Graphics (TVCG), minor revision (2018)
We introduce a data-driven method to generate a large number of plausible, closely interacting 3D human pose-pairs, for a given motion category, e.g., wrestling or salsa dance. With much difficulty in acquiring close interactions using 3D sensors, our approach utilizes abundant existing video data which cover many human activities. Instead of treating the data generation problem as one of reconstruction, we present a solution based on Markov Chain Monte Carlo (MCMC) sampling. Given a motion category and a set of video frames depicting the motion with the 2D pose-pair in each frame annotated, we start the sampling with one or few seed 3D pose-pairs which are manually created based on the target motion category. The initial set is then augmented by MCMC sampling around the seeds, via the Metropolis-Hastings algorithm and guided by a probability density function (PDF) that is defined by two terms to bias the sampling towards 3D pose-pairs that are physically valid and plausible for the motion category.
[
![]() Paper
]
Paper
]

Manyi Li, Noa Fish, Lili Cheng, Changhe Tu, Daniel Cohen-Or, Hao Zhang, and Baoquan Chen
In Graphical Models (2018)
Shape dissimilarity is a fundamental problem with many applications such as shape exploration, retrieval, and classification. Given a collection of shapes, all existing methods develop a consistent global metric to compareand organize shapes. The global nature of the involved shape descriptors implies that overall shape appearanceis compared. These methods work well to distinguishshapes from different categories, but often fail for fine-grained classes within the same category. In this paper, we develop a dissimilarity metric for fine-grained classes by fusing together multiple distinctive metrics for different classes. The fused metric measures the dissimilarities among inter-class shapes by observing their unique traits.
[
![]() Paper
]
Paper
]
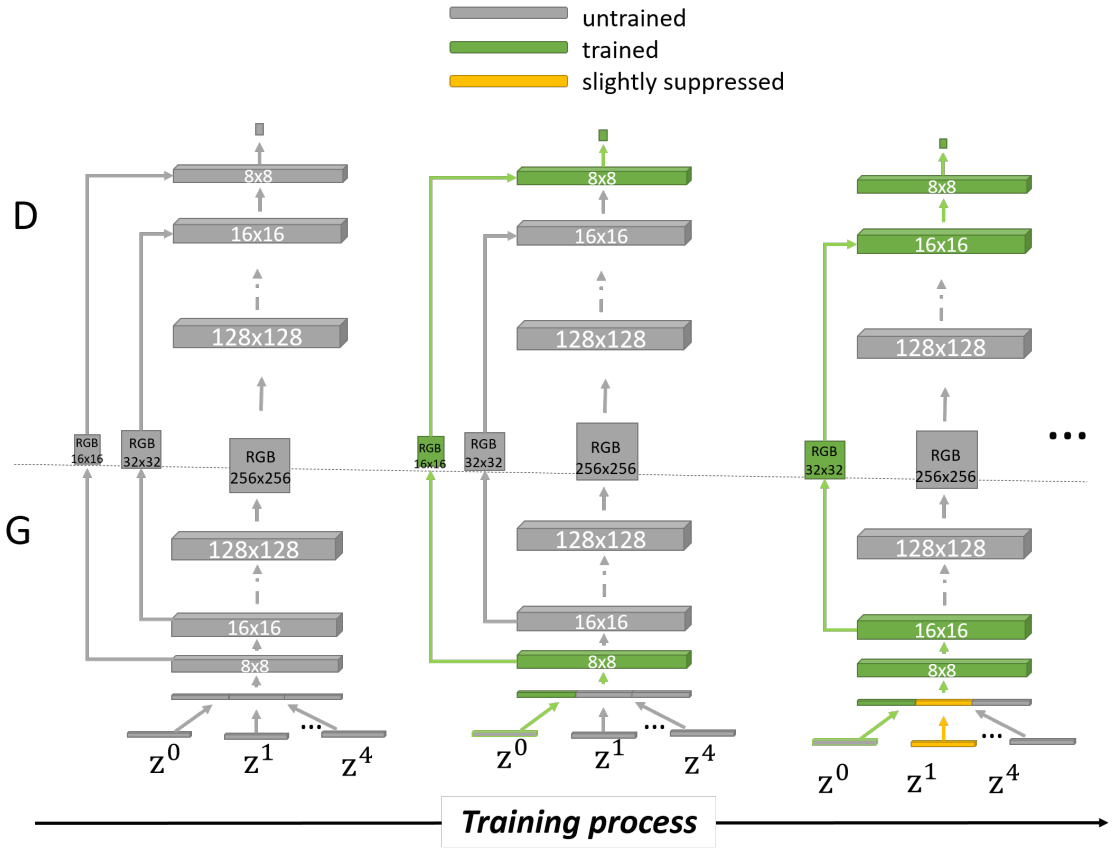
Zili Yi, Zhiqin Chen, Hao Zhang, Xin Huang, and Minglun Gong
In arXiv:1803.08467 (2018)
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators.
[
![]() Paper
]
Paper
]

Fenggen Yu, Yan Zhang, Kai Xu, Ali Mahdavi-Amiri, and Hao Zhang
In ACM Transactions on Graphics (2018)
We present a semi-supervised co-analysis method for learning 3D shape styles from projected feature lines, achieving style patch localization with only weak supervision. Given a collection of 3D shapes spanning multiple object categories and styles, we perform style co-analysis over projected feature lines of each 3D shape and then backproject the learned style features onto the 3D shapes.
[
![]() Paper
]
Paper
]
Ruizhen Hu, Wenchao Li, Oliver van Kaick, Ariel Shamir, Hao Zhang, and Hui Huang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia) (2017)
We introduce a method for learning a model for the mobility of parts in 3D objects. Our method allows not only to understand the dynamic function- alities of one or more parts in a 3D object, but also to apply the mobility functions to static 3D models. Specifically, the learned part mobility model can predict mobilities for parts of a 3D object given in the form of a single static snapshot reflecting the spatial configuration of the object parts in 3D space, and transfer the mobility from relevant units in the training data …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhaoliang Lun, Changqing Zou (joint first author), Haibin Huang, Evangelos Kalogerakis, Ping Tan, Marie-Paule Cani, and Hao Zhang
In ACM Transactions on Graphics (Special Issue of SIGGRAPH Asia) (2017)
We introduce a deep learning approach for grouping discrete patterns common in graphical designs. Our approach is based on a convolutional neural network architecture that learns a grouping measure defined over a pair of pattern elements. Motivated by perceptual grouping principles, the key feature of our network is the encoding of element shape, context, symmetries, and structural arrangements. These element properties are all jointly considered and appropriately weighted in our grouping measure …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong
In Proc. of ICCV (2017)
Conditional Generative Adversarial Networks (GANs) for cross-domain image-to-image translation have made much progress recently. Depending on the task complexity, thousands to millions of labeled image pairs are needed to train a conditional GAN. However, human labeling is expensive, even impractical, and large quantities of data may not always be available. Inspired by dual learning from natural language translation, we develop a novel dual-GAN mechanism, which enables image translators to be trained from two sets of unlabeled images from two domains. In our architecture, the primal GAN learns to translate images from domain U to those in domain V, while the dual GAN learns to invert the task. The closed loop made by the primal and dual tasks allows images from either domain to be translated and then reconstructed. Hence a loss function that accounts for the reconstruction error of images can be used to train the translators.
[
![]() Paper
]
Paper
]
Warunika Ranaweera, Parmit Chilana, Daniel Cohen-Or, and Hao Zhang
In International Conference on Computer-Aided Design and Computer Graphics (CAD/Graphics) (2017)
We introduce a shape modeling tool, ExquiMo, which is guided by the idea of improving the creativity of 3D shape designs through collaboration. Inspired by the game of Exquisite Corpse, our tool allocates distinct parts of a shape to multiple players who model the assigned parts in a sequence. Our approach is motivated by the understanding that effective surprise leads to creative outcomes. Hence, to maintain the surprise factor of the output, we conceal the previously modeled parts from the most recent player. Part designs from individual players are fused together to produce an often unexpected, hence creative, end result …
[
![]() Paper
]
Paper
]

Cui Z, Wang O, Tan P, Wang J.
In ACM Transactions on Graphics (SIGGRAPH 2017) (2017)
We propose an easy-to-use and robust system for creating time slice videos from a wide variety of consumer videos. The main technical challenge we address is how to align videos taken at different times with substantially different appearances, in the presence of moving objects and moving cameras with slightly different trajectories.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Zhu C, Yi R, Lira W, Alhashim I, Xu K, Zhang H.
In ACM Transactions on Graphics (SIGGRAPH 2017) (2017)
Many approaches to shape comparison and recognition start by establishing a shape correspondence. We “turn the table” and show that quality shape correspondences can be obtained by performing many shape recognition tasks.
[
![]() Paper
]
Paper
]

Hu R, Li W, van Kaick O, Huang H, Averkiou M, Cohen-Or D, Zhang H.
In ACM Transactions on Graphics (2017)
We introduce a method for co-locating style-defining elements over a set of 3D shapes. Our goal is to translate high-level style descriptions, such as “Ming” or “European” for furniture models, into explicit and localized regions over the geometric models that characterize each style. For each style, the set of style-defining elements is defined as the union of all the elements that are able to discriminate the style. Another property of the style-defining elements is that they are frequently-occurring, reflecting shape characteristics that appear across multiple shapes of the same style.
[
![]() Paper
]
Paper
]
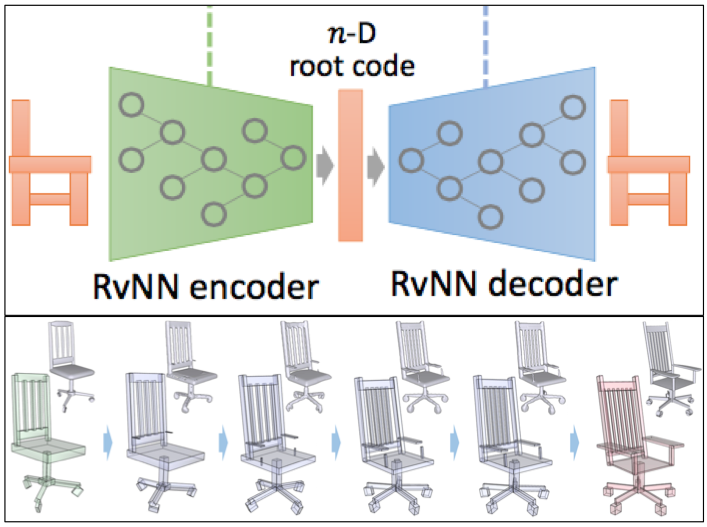
Li J, Xu K, Chaudhuri S, Yumer E, Zhang H, Guibas L.
In ACM Transactions on Graphics (SIGGRAPH 2017) (2017)
We introduce a novel neural network architecture for encoding and synthesis of 3D shapes, particularly their structures. Our key insight is that 3D shapes are effectively characterized by their hierarchical organization of parts, which reflects fundamental intra-shape relationships such as adjacency and symmetry. We develop a recursive neural net (RvNN) based autoencoder to map a flat, unlabeled, arbitrary part layout to a compact code.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
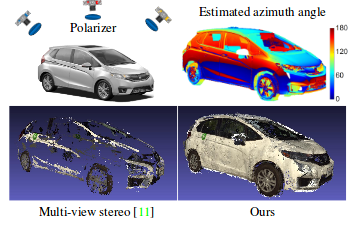
Cui Z, Gu J, Shi B, Tan P, Kautz J.
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2017)
We propose polarimetric multi-view stereo, which combines per-pixel photometric information from polarization with epipolar constraints from multiple views for 3D reconstruction. Polarization reveals surface normal information, and is thus helpful to propagate depth to featureless regions. Polarimetric multi-view stereo is completely passive and can be applied outdoors in uncontrolled illumination, since the data capture can be done simply with either a polarizer or a polarization camera.
[
![]() Paper
]
Paper
]

Rui Ma, Honghua Li, Changqing Zou, Zicheng Liao, Xin Tong, and Hao Zhang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 35, No. 6, Article 1736 (2016)
We introduce a framework for action-driven evolution of 3D indoor scenes, where the goal is to simulate how scenes are altered by human actions, and specifically, by object placements necessitated by the actions. To this end, we develop an action model with each type of action combining information about one or more human poses, one or more object categories, and spatial configurations of object-object and object-human relations for the action. Importantly, all these pieces of information are learned from annotated photos.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
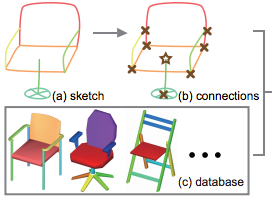
Lei Li, Zhe Huang, Changqing Zou, Chiew-Lan Tai, Rynson W.H. Lau, Hao Zhang, Ping Tan, and Hongbo Fu
In SIGGRAPH Asia Technical Brief (2016)
We propose an interactive system that aims at lifting a 2D sketch into a 3D sketch with the help of existing models in shape collections. The key idea is to exploit part structure for shape retrieval and sketch reconstruction. We adopt sketch-based shape retrieval and develop a novel matching algorithm which considers structure in addition to traditional shape features.
[
![]() Paper
]
Paper
]
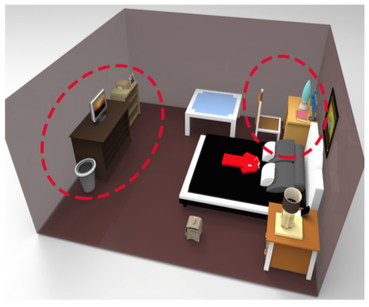
Zeinab Sadeghipour, Zicheng Liao, Ping Tan, and Hao Zhang
In Computer Graphics Forum (Special Issue of SGP), Vol. 35, No. 5, pp. 197-206 (2016)
We present a data-driven method for synthesizing 3D indoor scenes by inserting objects progressively into an initial, possibly, empty scene. Instead of relying on few hundreds of hand-crafted 3D scenes, we take advantage of existing large-scale annotated RGB-D datasets, in particular, the SUN RGB-D database consisting of 10,000+ depth images of real scenes, to form the prior knowledge for our synthesis task. Our object insertion scheme follows a co-occurrence model and an arrangement model, both learned from the SUN dataset.
[
![]() Paper
]
Paper
]

Ruizhen Hu, Oliver van Kaick, Bojian Wu, Hui Huang, Ariel Shamir, and Hao Zhang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 35, No. 4, Article 47 (2016)
We introduce a co-analysis method which learns a functionality model for an object category, e.g., strollers or backpacks. Like previous works on functionality, we analyze object-to-object interactions and intra-object properties and relations. Differently from previous works, our model goes beyond providing a functionalityoriented descriptor for a single object; it prototypes the functionality of a category of 3D objects by co-analyzing typical interactions involving objects from the category.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Changqing Zou, Junjie Cao, Warunika Ranaweera, Ibraheem Alhashim, Ping Tan, Alla Sheffer, and Hao Zhang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 35, No. 4, Article 122 (2016)
A calligram is an arrangement of words or letters that creates a visual image, and a compact calligram fits one word into a 2D shape. We introduce a fully automatic method for the generation of legible compact calligrams which provides a balance between conveying the input shape, legibility, and aesthetics.
[
![]() Paper
]
Paper
]
Haisen Zhao, Fanglin Gu, Qi-Xing Huang, Jorge Garcia, Yong Chen, Changhe Tu, Bedrich Benes, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 35, No. 4, Article 100 (2016)
We develop a new kind of “space-filling” curves, connected Fermat spirals, and show their compelling properties as a tool path fill pattern for layered fabrication. Unlike classical space-filling curves such as the Peano or Hilbert curves, which constantly wind and bind to preserve locality, connected Fermat spirals are formed mostly by long, low-curvature paths. This geometric property, along with continuity, influences the quality and efficiency of layered fabrication.
[
![]() Paper
]
Paper
]
Lili Wan, Changqing Zou, and Hao Zhang
In The Visual Computer (2016)
We introduce a novel approach to measure similarity between two 3D shapes based on sparse reconstruction of shape descriptors. The main feature of our approach is its applicability to handle incomplete shapes. We characterize the shapes by learning a sparse dictionary from their local descriptors. The similarity between two shapes A and B is defined by the error incurred when reconstructing B’s descriptor set using the basis signals from A’s dictionary.
[
![]() Paper
]
Paper
]

Daniel Cohen-Or and Hao Zhang
In Visual Computer (invited paper), Vol. 32, No. 1 (2016)
An intriguing and reoccurring question in many branches of computer science is whether machines can be creative, like humans. In this exploratory paper, we examine the problem from a computer graphics, and more specifically, geometric modeling, perspective. We focus our discussions on the weaker but still intriguing question: “Can machines assist or inspire humans in a creative endeavor for the generation of geometric forms?”
[
![]() Paper
]
Paper
]

Shuaicheng Liu, Ping Tan, Lu Yuan, Jian Sun, Bing Zeng
In European Conference on Computer Vision (ECCV) (2016)
Many existing video stabilization methods often stabilize videos off-line, i.e. as a postprocessing tool of pre-recorded videos. Some methods can stabilize videos online, but either require additional hardware sensors (e.g., gyroscope) or adopt a single parametric motion model (e.g., affine, homography) which is problematic to represent spatiallyvariant motions. In this paper, we propose a technique for online video stabilization with only one frame latency using a novel MeshFlow motion model. The MeshFlow is a spatial smooth sparse motion field with motion vectors only at the mesh vertexes.
[
![]() Paper
]
Paper
]

Wen-Yan Lin, Siying Liu, Nianjuan Jiang, Minh. N. Do, Ping Tan, Jianbo Lu
In European Conference on Computer Vision (ECCV) (2016)
A perennial problem in recovering 3-D models from images is repeated structures common in modern cities. The problem can be traced to the feature matcher which needs to match less distinctive features (permitting wide-baselines and avoiding broken sequences), while simultaneously avoiding incorrect matching of ambiguous repeated features. To meet this need, we develop RepMatch.

Luwei Yang, Ligeng Zhu, Yichen Wei, Shuang Liang, Ping Tan
In British Machine Vision Conference (BMVC) (2016)
Previous part-based attribute recognition approaches perform part detection and attribute recognition in separate steps. The parts are not optimized for attribute recognitionand therefore could be sub-optimal. We present an end-to-end deep learning approach to overcome the limitation.
[
![]() Paper
]
Paper
]
Changqing Zou, Tianfan Xue, Xiaojiang Peng, Honghua Li, Baochang Zhang, Ping Tan, Jianzhuang Liu
In Pattern Recognition,Vol. 60, pp. 543–553 (2016)
We propose an example-based approach for 3D man-made object reconstruction from single line drawings. Our approach can handle a wide range of 3D man-made objects including curved components.Comprehensive experiments show that the proposed approach outperforms previous work, especially for line drawings containing large degree of sketch errors.
[
![]() Paper
]
Paper
]

Boxin Shi, Zhe Wu, Zhipeng Mo, Dinglong Duan, Sai-Kit Yeung, Ping Tan
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2016)
In this paper, we first survey and categorize existing methods using a photometric stereo taxonomy emphasizing on non-Lambertian and uncalibrated methods. We then introduce the ‘DiLiGenT’ photometric stereo image dataset with calibrated Directional Lightings, objects of General reflectance, and ‘ground Truth’ shapes (normals).
[
![]() Paper
]
Paper
]

Renjiao Yi, Jue Wang, Ping Tan
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2016)
We present a fully automatic approach to detect and segment fence-like occluders from a video clip. Unlike previous approaches that usually assume either static scenes or cameras, our method is capable of handling both dynamic scenes and moving cameras. Under a bottom-up framework, it first clusters pixels into coherent groups using color and motion features. These pixel groups are then analyzed in a fully connected graph, and labeled as either fence or non-fence using graph-cut optimization. Finally, we solve a dense Conditional Random Filed (CRF) constructed from multiple frames to enhance both spatial accuracy and temporal coherence of the segmentation
[
![]() Paper
]
Paper
]

Alhashim I, Xu K, Zhuang Y, Cao J, Simari P, Zhang H.
In ACM Transactions on Graphics (Proc. of SIGGRAPH Asia) (2015)
We present a deformation-driven approach to topology-varying 3D shape correspondence. In this paradigm, the best correspondence between two shapes is the one that results in a minimal-energy, possibly topology-varying, deformation that transforms one shape to conform to the other while respecting the correspondence. Our deformation model, called GeoTopo transform, allows both geometric and topological operations such as part split, duplication, and merging, leading to fine-grained and piecewise continuous correspondence results. The key ingredient of our correspondence scheme is a deformation energy that penalizes geometric distortion, encourages structure preservation, and simultaneously allows topology changes. This is accomplished by connecting shape parts using structural rods, which behave similarly to virtual springs but simultaneously allow the encoding of energies arising from geometric, structural, and topological shape variations. Driven by the combined deformation energy, an optimal shape correspondence is obtained via a pruned beam search. We demonstrate our deformation-driven correspondence scheme on extensive sets of man-made models with rich geometric and topological variation and compare the results to state-of-the-art approaches.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Chen X, Zhou B, Lu F, Wang L, Bi L, Tan P.
In ACM Transactions on Graphics (Proc. of SIGGRAPH Asia) (2015)
We study the modeling of real garments and develop a system that is intuitive to use even for novice users. Our system includes garment component detectors and design attribute classifiers learned from a manually labeled garment image database. In the modeling time, we scan the garment with a Kinect and build a rough shape by KinectFusion from the raw RGBD sequence. The detectors and classifiers will identify garment components (e.g. collar, sleeve, pockets, belt, and buttons) and their design attributes (e.g. falbala collar or lapel collar, hubble-bubble sleeve or straight sleeve) from the RGB images. Our system also contains a 3D deformable template database for garment components. Once the components and their designs are determined, we choose appropriate templates, stitch them together, and fit them to the initial garment mesh generated by KinectFusion. Experiments on various different garment styles consistently generate high quality results.
[
![]() Paper
]
Paper
]

Chen X, Zhang H, Lin J, Hu R, Lu L, Huang Q, Benes B, Cohen-Or D, Chen B.
In ACM Transactions on Graphics (Proc. of SIGGRAPH Asia) (2015)
We pose the decompose-and-pack or DAP problem, which tightly combines shape decomposition and packing. While in general, DAP seeks to decompose an input shape into a small number of parts which can be efficiently packed, our focus is geared towards 3D printing. The goal is to optimally decompose-and-pack a 3D object into a printing volume to minimize support material, build time, and assembly cost. We present Dapper, a global optimization algorithm for the DAP problem which can be applied to both powder and FDM-based 3D printing. The solution search is top-down and iterative. Starting with a coarse decomposition of the input shape into few initial parts, we progressively pack a pile in the printing volume, by iteratively docking parts, possibly while introducing cuts, onto the pile. Exploration of the search space is via a prioritized and bounded beam search, with breadth and depth pruning guided by local and global DAP objectives.
[
![]() Paper
]
Paper
]

Zhou Y, Yin K, Huang H, Zhang H, Gong M, Cohen-Or D.
In ACM Transactions on Graphics (Proc. of SIGGRAPH Asia) (2015)
Decomposing a complex shape into geometrically simple primitives is a fundamental problem in geometry processing. We are interested in a shape decomposition problem where the simple primitives sought are generalized cylinders, which are ubiquitous in both organic forms and man-made artifacts. We introduce a quantitative measure of cylindricity for a shape part and develop a cylindricity-driven optimization algorithm, with a global objective function, for generalized cylinder decomposition. As a measure of geometric simplicity and following the minimum description length principle, cylindricity is defined as the cost of representing a cylinder through skeletal and cross-section profile curves. Our decomposition algorithm progressively builds local to non-local cylinders, which form over-complete covers of the input shape. The over-completeness of the cylinder covers ensures a conservative buildup of the cylindrical parts, leaving the final decision on decomposition to global optimization. We solve the global optimization by finding an exact cover, which optimizes the global objective function.

Li H, Hu R, Alhashim I, Zhang H.
In ACM Transactions on Graphics (Special Issue of SIGGRAPH) (2015)
We introduce the foldabilization problem for space-saving furniture design. Namely, given a 3D object representing a piece of furniture, our goal is to apply a minimum amount of modification to the object so that it can be folded to save space — the object is thus foldabilized. We focus on one instance of the problem where folding is with respect to a prescribed folding direction and allowed object modifications include hinge insertion and part shrinking.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
![]()
Hu R, Zhu C, van Kaick O, Liu L, Shamir A, Zhang H.
In ACM Transactions on Graphics (Special Issue of SIGGRAPH) (2015)
We introduce a contextual descriptor which aims to provide a geometric description of the functionality of a 3D object in the context of a given scene. Differently from previous works, we do not regard functionality as an abstract label or represent it implicitly through an agent. Our descriptor, called interaction context or ICON for short, explicitly represents the geometry of object-to-object interactions. Our approach to object functionality analysis is based on the key premise that functionality should mainly be derived from interactions between objects and not objects in isolation. Specifically, ICON collects geometric and structural features to encode interactions between a central object in a 3D scene and its surrounding objects. These interactions are then grouped based on feature similarity, leading to a hierarchical structure.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Li Z, Tan P, Tan RT, Zou D, Zhou SZhiying, Cheong L-F.
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
In our formulation, the depth cues from stereo matching and fog information reinforce each other, and produce superior results than conventional stereo or defogging algorithms. We first improve the photo-consistency term to explicitly model the appearance change due to the scattering effects. The prior matting Laplacian constraint on fog transmission imposes a detail preserving smoothness constraint on the scene depth. We further enforce the ordering consistency between scene depth and fog transmission at neighboring points.
Li H, Zhang H. editors:: M. Breu, A. Bruckstein, P. Maragos, and S. Wuhrer,
In (2015)
We cover techniques designed for compaction of shape representations or shape configurations. The goal of compaction is to reduce storage space, a fundamental problem in many application domains.
[
![]() Paper
]
Paper
]

Averbuch-Elor H, Wang Y, Qian Y, Gong M, Kopf J, Zhang H, Cohen-Or D.
In Computer Graphics Forum (Special Issue of Eurographics 2015) (2015)
We present a distillation algorithm which operates on a large, unstructured, and noisy collection of internet images returned from an online object query. We introduce the notion of a distilled set, which is a clean, coherent, and structured subset of inlier images. In addition, the object of interest is properly segmented out throughout the distilled set. Our approach is unsupervised, built on a novel clustering scheme, and solves the distillation and object segmentation problems simultaneously.
[
![]() Paper
]
Paper
]

Zheng Q, Hao Z, Huang H, Xu K, Zhang H, Cohen-Or D, Chen B.
In Computer Graphics Forum (Special Issue of Eurographics 2015) (2015)
Enhancing the self-symmetry of a shape is of fundamental aesthetic virtue. In this paper, we are interested in recov- ering the aesthetics of intrinsic reflection symmetries, where an asymmetric shape is symmetrized while keeping its general pose and perceived dynamics. The key challenge to intrinsic symmetrization is that the input shape has only approximate reflection symmetries, possibly far from perfect. The main premise of our work is that curve skeletons provide a concise and effective shape abstraction for analyzing approximate intrinsic symmetries as well as symmetrization.
[
![]() Paper
]
Paper
]

Liu Z., Xie C., Bu S., Wang X., Zhang H..
In Computer & Graphics (Special Issue of SMI 2014) (2015)
We introduce indirect shape analysis, or ISA, where a given shape is analyzed not based on geometric or topological features computed directly from the shape itself, but by studying how external agents interact with the shape. The potential benefits of ISA are two-fold. First, agent-object interactions often reveal an object’s function, which plays a key role in shape understanding. Second, compared to direct shape analysis, ISA, which utilizes pre-selected agents, is less affected by imperfections of, or inconsistencies between, the geometry or topology of the analyzed shapes.
[ ]

Cui Z, Jiang N, Tang C, Tan P.
In British Machine Vision Conference (BMVC) (2015)
This paper derives a novel linear position constraint for cameras seeing a common scene point, which leads to a direct linear method for global camera translation estimation. Unlike previous solutions, this method deals with collinear camera motion and weak image association at the same time. The final linear formulation does not involve the coordinates of scene points, which makes it efficient even for large scale data. We solve the linear equation based on $L_1$ norm, which makes our system more robust to outliers in essential matrices and feature correspondences. We experiment this method on both sequentially captured images and unordered Internet images. The experiments demonstrate its strength in robustness, accuracy, and efficiency.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Cui Z, Tan P.
In IEEE International Conference on Computer Vision (ICCV) (2015)
Global structure-from-motion (SfM) methods solve all cameras simultaneously from all available relative motions. It has better potential in both reconstruction accuracy and computation efficiency than incremental methods. However, global SfM is challenging, mainly because of two reasons. Firstly, translation averaging is difficult, since an essential matrix only tells the direction of relative translation. Secondly, it is also hard to filter out bad essential matrices due to feature matching failures. We propose to compute a sparse depth image at each camera to solve both problems. Depth images help to upgrade an essential matrix to a similarity transformation, which can determine the scale of relative translation. Thus, camera registration is formulated as a well-posed similarity averaging problem. Depth images also make the filtering of essential matrices simple and effective. In this way, translation averaging can be solved robustly in two convex L1 optimization problems, which reach the global optimum rapidly. We demonstrate this method in various examples including sequential data, Internet data, and ambiguous data with repetitive scene structures.
[
![]() Video
]
Video
]

Ruizhen Hu, Honghua Li, Hao Zhang, and Daniel Cohen-Or
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 33, No. 6, Article 213 (2014)
A shape is pyramidal if it has a flat base with the remaining boundary forming a height function over the base. Pyramidal shapes are optimal for molding, casting, and layered 3D printing. We introduce an algorithm for approximate pyramidal shape decomposition. The general exact pyramidal decomposition problem is NP-hard. We turn this problem into an NP-complete Exact Cover Problem which admits a practical solution … Our solution is equally applicable to 2D or 3D shapes, to shapes with polygonal or smooth boundaries, with or without holes …
[
![]() Paper
]
Paper
]

Kangxue Yin, Hui Huang, Hao Zhang, Minglun Gong, Daniel Cohen-Or, and Baoquan Chen
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 33, No. 6, Article 202 (2014)
We present an interactive technique for surface reconstruction from incomplete and sparse scans of 3D objects possessing sharp features … We factor 3D editing by the user into two “orthogonal” interactions acting on skeletal and profile curves of the underlying shape, controlling its topology and geometric features, respectively. For surface completion, we introduce a novel skeleton-driven morph-to-fit, or morfit, scheme which reconstructs the shape as an ensemble of generalized cylinders. Morfit is a hybrid operator which optimally interpolates between adjacent curve profiles (the “morph”) and snaps the surface to input points (the “fit”) …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
![]()
Ibraheem Alhashim, Honghua Li, Kai Xu, Junjie Cao, Rui Ma, and Hao Zhang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 33, No. 4, Article 158 (2014)
We introduce an algorithm for generating novel 3D models via topology-varying shape blending. Given a source and a target shape, our method blends them topologically and geometrically, producing continuous series of in-betweens as new shape creations. The blending operations are defined on a spatio-structural graph composed of medial curves and sheets. Such a shape abstraction is structure-oriented, part-aware, and facilitates topology manipulations. Fundamental topological operations including split and merge are realized by allowing one-to-many correspondences between the source and the target ..
[
![]() Project Page
|
Project Page
|
![]() Video
|
Video
|
![]() Slides
]
Slides
]
Kai Xu, Rui Ma, Hao Zhang, Chenyang Zhu, Ariel Shamir, Daniel Cohen-Or, and Hui Huang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 33, No. 4, Article 35 (2014)
We introduce focal points for characterizing, comparing, and organizing collections of complex and heterogeneous data and apply the concepts and algorithms developed to collections of 3D indoor scenes. We represent each scene by a graph of its constituent objects and define focal points as representative substructures in a scene collection. To organize a heterogenous scene collection, we cluster the scenes based on a set of extracted focal points: scenes in a cluster are closely connected when viewed from the perspective of the representative focal points of that cluster … The problem of focal point extraction is intermixed with the problem of clustering groups of scenes based on their representative focal points. We present a co-analysis algorithm …
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Slides
]
Slides
]
Xiaowu Chen, Dongqing Zou, Jianwei Li, Xiaochun Cao, Qinping Zhao, and Hao Zhang
In Proceedings of IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2014)
We introduce the use of sparse representation for edit propagation of high-resolution images or video. Previous approaches for edit propagation typically employ a global optimization over the whole set of image pixels, incurring a prohibitively high memory and time consumption for high-resolution images. Rather than propagating an edit pixel by pixel, we follow the principle of sparse representation to obtain a compact set of representative samples (or features) and perform edit propagation on the samples instead …
[
![]() Paper
]
Paper
]
Hui Wang, Patricio Simari, Zhixun Su, and Hao Zhang
In Proc. of Graphics Interface (2014)
We introduce spectral Global Intrinsic Symmetry Invariant Functions (GISIFs), a class of GISIFs obtained via eigendecomposition of the Laplace-Beltrami operator on compact Riemannian manifolds. We discretize the spectral GISIFs for 2D manifolds approximated either by triangle meshes or point clouds. In contrast to GISIFs obtained from geodesic distances, our spectral GISIFs are robust to local topological changes. Additionally, for symmetry analysis our spectral GISIFs can be viewed as generalizations of the classical Heat (HKSs) and Wave Kernel Signatures (WKSs), and, as such, represent a more expressive and versatile class of functions …
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Slides
]
Slides
]
Boxin Shi, Kenji Inose, Yasuyuki Matsushita, Ping Tan, Sai-Kit Yeung, Katsushi Ikeuchi
In International Conference on 3D Vision (3DV) (2014)
Photometric stereo using unorganized Internet images is very challenging, because the input images are captured under unknown general illuminations, with uncontrolled cameras. We propose to solve this difficult problem by a simple yet effective approach that makes use of a coarse shape prior. The shape prior…
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Shuaicheng Liu, Jue Wang, Sunghyun Cho, Ping Tan
In ACM Transaction on Graphics(TOG) and Proc. of SIGGRAPH Asia (2014)
In this work we propose a system to generate realistic, 3D-aware tracking shots from consumer videos. We show how computer vision techniques such as segmentation and structure-from-motion can be used to lower the barrier and help novice users create high quality tracking shots that are physically plausible
[
![]() Paper
]
Paper
]

Yinting Wang, Dacheng Tao, Xiang Li, Mingli Song, Jiajun Bu, Ping Tan
In IEEE Transaction on Image Processing (TIP), Vol 23, No. 11, pp. 4838–4849 (2014)
We address the problem of removing video color tone jitter that is common in amateur videos recorded with handheld devices. To achieve this, we introduce color state to represent the exposure and white balance state of a frame
[
![]() Paper
]
Paper
]

Yinda Zhang, Shuran Song, Ping Tan, Jianxiong Xiao
In European Conference on Computer Vision (ECCV) (2014)
We address the problem of removing video color tone jitter that is common in amateur videos recorded with handheld devices. To achieve this, we introduce color state to represent the exposure and white balance state of a frame
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Kun Li, Rui Huang, Swee King Phang, Shupeng Lai, Fei Wang, Ping Tan, Ben M. Chen, Tong Heng Lee
In International Micro Air Vehicle Conference and Competition (2014)
We propose an approach to autonomously control a quadrotor micro aerial vehicle (MAV). With take-off weight of 50 g and 8-min flight endurance, the MAV platform codenamed ‘KayLion’ developed by the National University of Singapore (NUS) is able to perform autonomous flight with pre-planned path tracking
[
![]() Paper
]
Paper
]
Shuaicheng Liu, Lu Yuan, Ping Tan, Jian Sun
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2014)
We propose a novel motion model, SteadyFlow, to represent the motion between neighboring video frames for stabilization. A SteadyFlow is a specific optical flow by enforcing strong spatial coherence, such that smoothing feature trajectories can be replaced by smoothing pixel profiles….
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
Wang Y, Gong M, Wang T, Cohen-Or D, Zhang H, Chen B.
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia) (2013)
We introduce projective analysis for semantic segmentation and labeling of 3D shapes. The analysis treats an input 3D shape as a collection of 2D projections, labels each projection by transferring knowledge from existing labeled images, and back-projects and fuses the labelings on the 3D shape. The image-space analysis involves matching projected binary images of 3D objects based on a novel bi-class Hausdorff distance.
[
![]() Paper
]
Paper
]
Zhang H, Xu K, Jiang W, Lin J, Cohen-Or D, Chen B.
In ACM Trans. on Graphics (Special Issue of SIGGRAPH) (2013)
We present an algorithm for hierarchical and layered analysis of irregular facades, seeking a high-level understanding of facade structures. By introducing layering into the analysis, we no longer view a facade as a flat structure, but allow it to be structurally separated into depth layers, enabling more compact and natural interpretations of building facades.
[
![]() Paper
]
Paper
]
van Kaick O, Xu K, Zhang H, Wang Y, Sun S, Shamir A, Cohen-Or D.
In ACM Trans. on Graphics (Proc. SIGGRAPH) (2013)
We introduce an unsupervised co-hierarchical analysis of a set of shapes, aimed at discovering their hierarchical part structures and revealing relations between geometrically dissimilar yet functionally equivalent shape parts across the set. The core problem is that of representative co-selection. For each shape in the set, one representative hierarchy (tree) is selected from among many possible interpretations of the hierarchical structure of the shape. Collectively, the selected tree representatives maximize the within-cluster structural similarity among them. We develop an iterative algorithm for representative co-selection. At each step, a novel cluster-and-select scheme is applied to a set of candidate trees for all the shapes. The tree-to-tree distance for clustering caters to structural shape analysis by focusing on spatial arrangement of shape parts, rather than their geometric details. The final set of representative trees are unified to form a structural co-hierarchy. We demonstrate co-hierarchical analysis on families of man-made shapes exhibiting high degrees of geometric and finer-scale structural variabilities.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Huang H, Wu S, Cohen-Or D, Gong M, Zhang H, Li G, Chen B.
In ACM Trans. on Graphics (Special Issue of SIGGRAPH) (2013)
We introduce L1-medial skeleton as a curve skeleton representation for 3D point cloud data. The L1-median is well-known as a robust global center of an arbitrary set of points. We make the key observation that adapting L1-medians locally to a point set representing a 3D shape gives rise to a one-dimensional structure, which can be seen as a localized center of the shape.
[
![]() Paper
]
Paper
]
Huang S-S, Shamir A, Shen C-H, Zhang H, Sheffer A, Hu S-M, Cohen-Or D.
In ACM Trans. on Graphics (Special Issue of SIGGRAPH) (2013)
We present a method for organizing a heterogeneous collection of 3D shapes for overview and exploration. Instead of relying on quantitative distances, which may become unreliable between dissimilar shapes, we introduce a qualitative analysis which utilizes multiple distance measures but only in cases where the measures can be reliably compared. Our analysis is based on the notion of quartets , each defined by two pairs of shapes, where the shapes in each pair are close to each other, but far apart from the shapes in the other pair. Combining the information from many quartets computed across a shape collection using several distance measures, we create a hierarchical structure we call categorization tree of the shape collection. This tree satisfies the topological (qualitative) constraints imposed by the quartets creating an effective organi- zation of the shapes.
van Kaick O, Zhang H, Hamarneh G.
In Computer Graphics Forum. to appear (2013)
We introduce the bilateral map, a local shape descriptor whose region of interest is defined by two feature points. Compared to the classical descriptor definition using a single point, the bilateral approach exploits the use of a second point to place more constraints on the selection of the spatial context for feature analysis. This leads to a descriptor where the shape of the region of interest adapts to the context of the two points, making it more refined for shape matching. In particular, we show that our new descriptor is more effective for partial matching, since potentially extraneous regions of the models are selectively ignored owing to the adaptive nature of the bilateral map.
[
![]() Paper
]
Paper
]
Liu Z, Tang S, Bu S, Zhang H.
In Computer & Graphics (Special issue of SMI) (2013)
We propose two novel metrics to support comparison with multiple ground-truth segmentations, which are named Similarity Hamming Distance (SHD) and Adaptive Entropy Increment (AEI). SHD is based on partial similarity correspondences between automatic segmentation and ground-truth segmentations, and AEI measures entropy change when an automatic segmentation is added to a set of different ground-truth segmentations. A group of experiments demonstrates that the metrics are able to provide relatively higher discriminative power and stability when evaluating different hierarchical segmentations, and also provide an effective evaluation more consistent with human perception.
[
![]() Paper
]
Paper
]
Mitra N, Wand M, Zhang H, Cohen-Or D, Bokeloh M.
In Eurographics State-of-the-art Report (STAR) (2013)
We organize, summarize, and present the key concepts and methodological approaches towards efficient structure-aware shape processing. We discuss common models of structure, their implementation in terms of mathematical formalism and algorithms, and explain the key principles in the context of a number of state-of-the-art approaches. Further, we attempt to list the key open problems and challenges, both at the technical and at the conceptual level, to make it easier for new researchers to better explore and contribute to this topic. Our goal is to both give the practitioner an overview of available structure-aware shape processing techniques, as well as identify future research questions in this important, emerging, and fascinating research area.
[
![]() Paper
]
Paper
]

Li H, Zhang H, Wang Y, Cao J, Shamir A, Cohen-Or D.
In Computer Graphics Forum. :toappear (2013)
The word “style” can be interpreted in so many different ways in so many different contexts. To provide a general analysis and understanding of styles is a highly challenging problem. We pose the open question “how to extract styles from geometric shapes?” and address one instance of the problem. Specifically, we present an unsupervised algorithm for identifying curve styles in a set of shapes. In our setting, a curve style is explicitly represented by a mode of curve features appearing along the 2D silhouettes of the shapes in the set. Unlike previous attempts, we do not rely on any preconceived conceptual characterizations, e.g., via specific shape descriptors, to define what is or is not a style. Our definition of styles is data-dependent ; it depends on the input set but we do not require computing a shape correspondence across the set. We provide an operational definition of curve styles which focuses on separating curve features that represent styles from curve features that are content-revealing. To this end, we develop a novel formulation and associated algorithm for style-content separation. The analysis is based on a feature-shape association matrix (FSM) whose rows correspond to modes of curve features, columns to shapes in the set, and each entry expresses the extent a feature mode is present in a shape.
[
![]() Paper
]
Paper
]
Huang H, Wu S, Gong M, Cohen-Or D, Ascher U, Zhang H.
In ACM Trans. on Graphics (2013)
Points acquired by laser scanners are not intrinsically equipped with normals, which are essential to surface reconstruction and point set rendering using surfels. Normal estimation is notoriously sensitive to noise. Near sharp features, the computation of noise-free normals becomes even more challenging due to the inherent undersampling problem at edge singularities. As a result, common edge-aware consolidation techniques such as bilateral smoothing may still produce erroneous normals near the edges. We propose a resampling approach to process a noisy and possibly outlier-ridden point set in an edge-aware manner. Our key idea is to first resample away from the edges so that reliable normals can be computed at the samples, and then based on reliable data, we progressively resample the point set while approaching the edge singularities. We demonstrate that our Edge-Aware Resampling (EAR) algorithm is capable of producing consolidated point sets with noise-free normals and clean preservation of sharp features. We also show that EAR leads to improved performance of edge-aware reconstruction methods and point set rendering techniques.
[
![]() Paper
]
Paper
]

Jiang N, Cui Z, Tan P.
In IEEE International Conference on Computer Vision (ICCV) (2013)
We present a linear method for global camera pose registration from pair wise relative poses encoded in essential matrices. Our method minimizes an approximate geometric error to enforce the triangular relationship in camera triplets. This formulation does not suffer from the typical `unbalanced scale’ problem in linear methods relying on pair wise translation direction constraints, i.e. an algebraic error, nor the system degeneracy from collinear motion. In the case of three cameras, our method provides a good linear approximation of the trifocal tensor. It can be directly scaled up to register multiple cameras. The results obtained are accurate for point triangulation and can serve as a good initialization for final bundle adjustment. We evaluate the algorithm performance with different types of data and demonstrate its effectiveness. Our system produces good accuracy, robustness, and outperforms some well-known systems on efficiency.
[
![]() Paper
]
Paper
]
Kai Xu, Hao Zhang, Wei Jiang, Ramsay Dyer, Zhiquan Cheng, Ligang Liu, and Baoquan Chen
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 31, No. 6, Article 181 (2012)
We present an algorithm for multi-scale partial intrinsic symmetry detection over 2D and 3D shapes, where the scale of a symmetric region is defined by intrinsic distances between symmetric points over the region. To identify prominent symmetric regions which overlap and vary in form and scale, we decouple scale extraction and symmetry extraction by performing two levels of clustering. First, significant symmetry scales are identified by clustering sample point pairs from an input shape …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Honghua Li, Ibraheem Alhashim, Hao Zhang, Ariel Shamir, and Daniel Cohen-Or
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 31, No. 6, Article 158 (2012)
We introduce the geometric problem of stackabilization: how to geometrically modify a 3D object so that it is more amenable to stacking. Given a 3D object and a stacking direction, we define a measure of stackability, which is derived from the gap between the lower and upper envelopes of the object in a stacking configuration along the stacking direction. The main challenge in stackabilization lies in the desire to modify the object’s geometry only subtly so that the intended functionality and aesthetic appearance of the original object are not significantly affected …
[
![]() Paper
]
Paper
]
Hui Huang, Minglun Gong, Daniel Cohen-Or, Yaobin Ouyang, Fuwen Tao, and Hao Zhang
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 31, No. 6, Article 179 (2012)
We present an automatic shape composition method to fuse two shape parts which may not overlap and possibly contain sharp features, a scenario often encountered when modeling man-made objects. At the core of our method is a novel field-guided approach to automatically align two input parts in a feature-conforming manner. The key to our field-guided shape registration is a natural continuation of one part into the ambient field as a means to introduce an overlap with the distant part, which then allows a surface-to-field registration …
[
![]() Paper
]
Paper
]
Yunhai Wang, Shmulik Asafi, Oliver van Kaick, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen
In ACM Trans. on Graphics (Special Issue of SIGGRAPH Asia), Vol. 31, No. 6, Article 165 (2012)
We consider the use of a semi-supervised learning method where the user actively assists in the co-analysis by iteratively providing input that progressively constrains the system. We introduce a novel constrained clustering method based on a spring system which embeds elements to better respect their inter-distances in feature space together with the user given set of constraints. We also present an active learning method that suggests to the user where his input is likely to be the most effective in refining the results.
[
![]() Paper
]
Paper
]
Nima Aghdaii, Hamid Younesy, and Hao Zhang
In Computer & Graphics, extended version of GI’12 paper, Vol. 36, No. 8, pp. 1072-1083 (2012)
We introduce a new type of meshes called 5-6-7 meshes, analyze their properties, and present a 5-6-7 remeshing algorithm. A 5-6-7 mesh is a closed triangle mesh where each vertex has valence 5, 6, or 7. We prove that it is always possible to convert an arbitrary mesh into a 5-6-7 mesh. We present a remeshing algorithm which converts a closed triangle mesh with arbitrary genus into a 5-6-7 mesh which a) closely approximates the original mesh geometrically, e.g., in terms of feature preservation, and b) has a comparable vertex count as the original mesh.
[
![]() Paper
]
Paper
]

Andrea Tagliassachi, Ibraheem Alhashim, Matt Olson, and Hao Zhang
In Computer Graphics Forum (Special Issue of SGP), Volume 31, Number 5, pp. 1735-1744 (2012)
We formulate the skeletonization problem via mean curvature flow (MCF). While the classical application of MCF is surface fairing, we take advantage of its area-minimizing characteristic to drive the curvature flow towards the extreme so as to collapse the input mesh geometry and obtain a skeletal structure. By analyzing the differential characteristics of the flow, we reveal that MCF locally increases shape anisotropy. This justifies the use of curvature motion for skeleton computation, and leads to the generation of what we call “mean curvature skeletons” …
[
![]() Paper
]
Paper
]

Kai Xu, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen
In ACM Trans. on Graphics (Special Issue of SIGGRAPH), Vol. 31, No. 4, pp. 57:1-57:10 (2012)
We introduce set evolution as a means for creative 3D shape modeling, where an initial population of 3D models is evolved to produce generations of novel shapes. Part of the evolving set is presented to a user as a shape gallery to offer modeling suggestions. User preferences define the fitness for the evolution so that over time, the shape population will mainly consist of individuals with good fitness. However, to inspire the user’s creativity, we must also keep the evolving set diverse. Hence the evolution is ``fit and diverse’’ …
[
![]() Paper
]
Paper
]
Nima Aghdaii, Hamid Younesy, and Hao Zhang
In Proc. of Graphics Interface, pp. 27-34 (2012)
A 5-6-7 mesh is a closed triangle mesh where each vertex has valence 5, 6, or 7. An intriguing question is whether it is always possible to convert an arbitrary mesh into a 5-6-7 mesh. In this paper, we answer the question in the positive. We present a 5-6-7 remeshing algorithm which converts any closed triangle mesh with arbitrary genus into a 5-6-7 mesh which a) closely approximates the original mesh geometrically, e.g., in terms of feature preservation, and b) has a comparable vertex count as the original mesh.
[
![]() Paper
]
Paper
]
Hui Wang, Zhixun Su, Jinjie Cao, Ye Wang, and Hao Zhang
In Graphical Models (Special Issue of GMP), Vol. 74, No. 4, pp. 173-183 (2012)
Empirical Mode Decomposition (EMD) is a powerful tool for the analysis of non-stationary and nonlinear signals, and has drawn a great deal of attention in various areas. In this paper, we generalize the classical EMD from Euclidean space to surfaces represented as triangular meshes. Inspired by the EMD, we also make a first step in using the extremal envelope method for feature-preserving smoothing.
[
![]() Paper
]
Paper
]
![]()
Ibraheem Alhashim, Hao Zhang, and Ligang Liu
In the Visual Computer, Vol. 28, No. 12, pp. 1153-1166 (2012)
We propose a simple and efficient method that helps create model variations by applying non-uniform stretching on 3D models with organic geometric details. The method replicates the geometric details and synthesizes extensions by adopting texture synthesis techniques on surface details.

Zhenglong Zhou, Bo Shu, Shaojie Zhuo, Xiaoming Deng, Ping Tan, Stephen Lin
In SIGGRAPH Asia Technique Briefs (2012)
We propose an image-based approach for virtual clothes fitting, in which a user moves freely in front of a virtual mirror (i.e., video screen) that displays the user wearing a superimposed virtual garment.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Xiaowu Chen, Dongqing Zou, Qinping Zhao, Ping Tan
In ACM Transaction on Graphics(TOG) and Proc. of SIGGRAPH Asia (2012)
We propose a novel edit propagation algorithm for interactive image and video manipulations. Our approach uses the locally linear embedding (LLE) to represent each pixel as a linear combination of its neighbors in a feature space
[
![]() Paper
]
Paper
]

Yinting Wang, Jiajun Bu, Na Li, Mingli Song, Ping Tan
In International Conference on Pattern Recognition (ICPR) (2012)
A method is described for discontinuity detection in pictorial data. It computes at each point a planar approximation of the data and uses the statistics of the differences between the actual values and the approximations for detection of both steps and creases. The use of local statistical properties in the residuals provides…..
[
![]() Paper
]
Paper
]

Tao Chen, Ping Tan, Li-Qian Ma, Ming-Ming Cheng, Ariel Shamir, Shi-Min Hu
In IEEE Transaction on Visualization and Computer Graphics (TVCG) (2012)
We present PoseShop – a pipeline to construct segmented human image database with minimal manual intervention. By downloading, analyzing, and filtering massive amounts of human images….
[
![]() Paper
]
Paper
]

Hanqing Jiang, Haomin Liu, Ping Tan, Guofeng Zhang, Hujun Bao
In European Conference on Computer Vision (ECCV) (2012)
We propose a novel dense depth estimation method which can automatically recover accurate and consistent depth maps from the synchronized video sequences taken by a few handheld cameras. Unlike fixed camera arrays…
[
![]() Paper
]
Paper
]

Kyong Joon Lee, Qi Zhao, Xin Tong, Minmin Gong, Shahram Izadi, Sang Uk Lee, Ping Tan, Stephen Lin
In European Conference on Computer Vision (ECCV) (2012)
We present a technique for estimating intrinsic images from image+depth video, such as that acquired from a Kinect camera. Intrinsic image decomposition in this context has importance in applications like object modeling, in which surface colors need to be recovered without illumination effects. The proposed method is based on two new types of decomposition constraints
[
![]() Paper
]
Paper
]

Boxin Shi, Ping Tan, Yasuyuki Matsushita, Katsushi Ikeuchi
In European Conference on Computer Vision (ECCV) (2012)
This paper exploits the monotonicity of general isotropic re-flectances for estimating elevation angles of surface normal given the azimuth angles. With an assumption that the reflectance includes at least one lobe that is a monotonic function of the angle between the surface normal and half-vector (bisector of lighting and viewing directions), we prove that elevation angles can be uniquely
[
![]() Paper
]
Paper
]

Danping Zou, Ping Tan
In IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI) (2012)
This paper studies the problem of vision-based simultaneous localization and mapping (SLAM) in dynamic environments with multiple cameras. We introduce inter-camera pose estimation and inter-camera mapping to deal with dynamic objects in the localization and mapping process.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
Nianjuan Jiang, Ping Tan, Loong-Fah Cheong
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2012)
We propose a novel optimization criteria based on the idea of ‘missing correspondences’. The global minimum of our optimization objective function is associated with the correct solution. We then design an ef- ficient algorithm for minimization, whose convergence to a local minimum is guaranteed.
[
![]() Paper
]
Paper
]
Boxin Shi, Ping Tan, Yasuyuki Matsushita, Katsushi Ikeuchi.
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2012)
We propose a compact biquadratic reflectance model to represent the reflectance of a broad class of materials precisely in the low-frequency domain. We validate our model by fitting to both existing parametric models and non-parametric measured data, and show that our model outperforms existing parametric diffuse models. We show applications of reflectometry using general diffuse surfaces and photometric stereo for general isotropic materials
[
![]() Paper
]
Paper
]

Shuaicheng Liu, YintingWang, Lu Yuan, Jiajun Bu, Ping Tan, Jian Sun
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2012)
We propose to solve video stabilization with an additional depth sensor such as the Kinect camera. Though the depth image is noisy, incomplete and low resolution, it facilitates both camera motion estimation and frame warping, which makes the video stabilization a much well posed problem. The experiments demonstrate the effectiveness of our algorithm.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Qi Zhao, Ping Tan, Qiang Dai, Li Shen, Enhua Wu, Stephen Lin
In IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI) (2012)
We propose a method for intrinsic image decomposition based on Retinex theory and texture analysis. While most previous methods approach this problem by analyzing local gradient properties, our technique additionally identifies distant pixels with the same reflectance through texture analysis, and uses these non-local reflectance constraints to significantly reduce ambiguity in decomposition
[
![]() Paper
]
Paper
]
Torsney-Weir T, Saad A, Moeller T, Hege H-C, Weber B, Verbavatz J-M.
In IEEE transactions on visualization and computer graphics (2011)
In this paper we address the difficult problem of parameter-finding in image segmentation. We replace a tedious manual process that is often based on guess-work and luck by a principled approach that systematically explores the parameter space. Our core idea is the following two-stage technique: We start with a sparse sampling of the parameter space and apply a statistical model to estimate the response of the segmentation algorithm. The statistical model incorporates a model of uncertainty of the estimation which we use in conjunction with the actual estimate in (visually) guiding the user towards areas that need refinement by placing additional sample points. In the second stage the user navigates through the parameter space in order to determine areas where the response value (goodness of segmentation) is high. In our exploration we rely on existing ground-truth images in order to evaluate the “goodness” of an image segmentation technique. We evaluate its usefulness by demonstrating this technique on two image segmentation algorithms: a three parameter model to detect microtubules in electron tomograms and an eight parameter model to identify functional regions in dynamic Positron Emission Tomography scans.
[ ]

Sidi O, van Kaick O, Kleinman Y, Zhang H, Cohen-Or D.
In ACM Trans. on Graphics (Proc. of SIGGRAPH Asia) (2011)
We introduce an algorithm for unsupervised co-segmentation of a set of shapes so as to reveal the semantic shape parts and establish their correspondence across the set. The input set may exhibit significant shape variability where the shapes do not admit proper spatial alignment and the corresponding parts in any pair of shapes may be geometrically dissimilar. Our algorithm can handle such challenging input sets since, first, we perform co-analysis in a descriptor space, where a combination of shape descriptors relates the parts independently of their pose, location, and cardinality. Secondly, we exploit a key enabling feature of the input set, namely, dissimilar parts may be “linked” through third-parties present in the set. The links are derived from the pairwise similarities between the parts’ descriptors. To reveal such linkages, which may manifest themselves as anisotropic and non-linear structures in the descriptor space, we perform spectral clustering with the aid of diffusion maps. We show that with our approach, we are able to co-segment sets of shapes that possess significant variability, achieving results that are close to those of a supervised approach.
[
![]() Paper
]
Paper
]
van Kaick O, Zhang H, Hamarneh G, Cohen-Or D.
In Computer Graphics Forum (2011)
We review methods designed to compute correspondences between geometric shapes represented by triangle meshes, contours or point sets. This survey is motivated in part by recent developments in space–time registration, where one seeks a correspondence between non-rigid and time-varying surfaces, and semantic shape analysis, which underlines a recent trend to incorporate shape understanding into the analysis pipeline. Establishing a meaningful correspondence between shapes is often difficult because it generally requires an understanding of the structure of the shapes at both the local and global levels, and sometimes the functionality of the shape parts as well. Despite its inherent complexity, shape correspondence is a recurrent problem and an essential component of numerous geometry processing applications. In this survey, we discuss the different forms of the correspondence problem and review the main solution methods, aided by several classification criteria arising from the problem definition. The main categories of classification are defined in terms of the input and output representation, objective function and solution approach. We conclude the survey by discussing open problems and future perspectives
[
![]() Paper
]
Paper
]

Xu K, Zheng H, Zhang H, Cohen-Or D, Liu L, Xiong Y.
In ACM Transactions on Graphics (SIGGRAPH 2011) (2011)
We introduce an algorithm for 3D object modeling where the user draws creative inspiration from an object captured in a single photograph. Our method leverages the rich source of photographs for creative 3D modeling. However, with only a photo as a guide, creating a 3D model from scratch is a daunting task. We support the modeling process by utilizing an available set of 3D candidate models. Specifically, the user creates a digital 3D model as a geometric variation from a 3D candidate. Our modeling technique consists of two major steps. The first step is a user-guided image-space object segmentation to reveal the structure of the photographed object. The core step is the second one, in which a 3D candidate is automatically deformed to fit the photographed target under the guidance of silhouette correspondence. The set of candidate models have been pre-analyzed to possess useful high-level structural information, which is heavily utilized in both steps to compensate for the ill-posedness of the analysis and modeling problems based only on content in a single image. Equally important, the structural information is preserved by the geometric variation so that the final product is coherent with its inherited structural information readily usable for subsequent model refinement or processing.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Tagliasacchi A, Olson M, Zhang H, Hamarneh G, Cohen-Or D.
In Computer Graphics Forum (Proceedings of Symposium on Geometry Processing) (2011)
Objects with many concavities are difficult to acquire using laser scanners. The highly concave areas are hard to access by a scanner due to occlusions by other components of the object. The resulting point scan typically suffers from large amounts of missing data. Methods that use surface-based priors rely on local surface estimates and perform well only when filling small holes. When the holes become large, the reconstruction problem becomes severely under-constrained, which necessitates the use of additional reconstruction priors. In this paper, we introduce weak volumetric priors which assume that the volume of a shape varies smoothly and that each point cloud sample is visible from outside the shape. Specifically, the union of view-rays given by the scanner implicitly carves the exterior volume, while volumetric smoothness regularizes the internal volume. We incorporate these priors into a surface evolution framework where a new energy term defined by volumetric smoothness is introduced to handle large amount of missing data. We demonstrate the effectiveness of our method on objects exhibiting deep concavities, and show its general applicability over a broader spectrum of geometric scenario.
[
![]() Paper
]
Paper
]
Olson M, Dyer R, Zhang H, Sheffer A.
In Shape Modeling International (2011)
We present an algorithm to compute the silhouette set of a point cloud. Previous methods extract point set silhouettes by thresholding point normals, which can lead to simultaneous over- and under-detection of silhouettes. We argue that additional information such as surface curvature is necessary to resolve these issues.
[
![]() Paper
]
Paper
]
Wang Y, Xu K, Li J, Zhang H, Shamir A, Liu L, Cheng Z, Xiong Y.
In Computer Graphics Forum (Special Issue of Eurographics 2011) (2011)
We introduce symmetry hierarchy of man-made objects, a high-level structural representation of a 3D model providing a symmetry-induced, hierarchical organization of the model’s constituent parts. We show that symmetry hierarchy naturally implies a hierarchical segmentation that is more meaningful than those produced by local geometric considerations. We also develop an application of symmetry hierarchies for structural shape editing.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Kahlert J, Olson M, Zhang H.
In The Visual Computer (2011)
We present an algorithm for computing families of geodesic curves over an open mesh patch to partition the patch into strip-like segments. Specifically, the segments can be well approximated using strips obtained by trimming long, rectangular pieces of material possessing a prescribed width. We call this width-bounded geodesic strip tiling of a curved surface, a problem with practical applications such as the surfacing of curved roofs.
[
![]() Paper
]
Paper
]

van Kaick O., Tagliasacchi A., Sidi O., Zhang H., Cohen-Or D., Wolf L., Hamarneh G..
In Computer Graphics Forum (Proc. Eurographics) (2011)
We stipulate that in these cases, shape correspondence by humans involves recognition of the shape parts where prior knowledge on the parts would play a more dominant role than geometric similarity. We introduce an approach to part correspondence which incorporates prior knowledge imparted by a training set of pre-segmented, labeled models and combines the knowledge with content driven analysis based on geometric similarity between the matched shapes. First, the prior knowledge is learned from the training set in the form of per-label classifiers. Next, given two query shapes to be matched, we apply the classifiers to assign a probabilistic label to each shape face. Finally,by means of a joint labeling scheme, the probabilistic labels are used synergistically with pairwise assignments derived from geometric similarity to provide the resulting part correspondence.
[
![]() Paper
]
Paper
]

Molomey B., Ament M., Weiskopf D., Möller T.
In IEEE Transactions on Visualization and Computer Graphics (2011)
We demonstrate that sort first distributions are not only a viable method of performing data scalable parallel volume rendering, but more importan tly they allow for a range of rendering algorithms and techniques that are not efficient with sort last distributions. Several of these algorithms are discussed and two of them are implemented in a parallel environment: a new improved variant of early ray termination to speed up rendering when volumetric occlusion occurs and a volumetric shadowing technique that produces more realistic and infor mative images based on half angle slicing. Improved methods of distributing the computation of the load balancing and loading portions o f a subdivided data set are also presented. Our detailed test r esults for a typical GPU cluster with distributed memory show that our sort first rendering algorithm outperforms sort last rendering in many scenarios.
[
![]() Paper
]
Paper
]
Meng T., Entezari A., Smith B., Weiskopf D., Möller T.
In IEEE Transactions on Visualization and Computer Graphics (2011)
The Body-Centered Cubic (BCC) and Face-Centered Cubic (FCC) lattices have been analytically shown to be more efficient sampling lattices than the traditional Cartesian Cubic (CC) lattice, but there has been no estimate of their visual comparability. Two perceptual studies (each with N = 12 participants) compared the visual quality of images rendered from BCC and FCC lattices to images rendered from the CC lattice. Images were generated from two signals: the commonly used Marschner-Lobb synthetic function and a computed tomography scan of a fish tail. Observers found that BCC and FCC could produce images of comparable visual quality to CC, using 30-35 percent fewer samples. For the images used in our studies, the L(2) error metric shows high correlation with the judgement of human observers. Using the L(2) metric as a proxy, the results of the experiments appear to extend across a wide range of images and parameter choices.
[
![]() Paper
]
Paper
]
Hossain Z., Alim U.R., Möller T.
In IEEE Transactions on Visualization and Computer Graphics (2011)
We present two methods for accurate gradient estimation from scalar field data sampled on regular lattices. The first method is based on the multidimensional Taylor series expansion of the convolution sum and allows us to specify design criteria such as compactness and approximation power. The second method is based on a Hilbert space framework and provides a minimum error solution in the form of an orthogonal projection operating between two approximation spaces. Both methods lead to discrete filters, which can be combined with continuous reconstruction kernels to yield highly accurate estimators as compared to the current state of the art. We demonstrate the advantages of our methods in the context of volume rendering of data sampled on Cartesian and Body-Centered Cubic lattices. Our results show significant qualitative and quantitative improvements for both synthetic and real data, while incurring a moderate preprocessing and storage overhead.
[
![]() Paper
]
Paper
]

Kai Xu, Honghua Li, Hao Zhang, Daniel Cohen-Or, Yueshan Xiong, and Zhiquan Cheng
In ACM Trans. on Graphics (Proceeding of SIGGRAPH Asia 2010), Volume 29, Number 6, pp. 184:1-184:10 (2010)
We perform co-analysis of a set of man-made 3D objects to allow the creation of novel instances derived from the set. We analyze the objects at the part level and treat the anisotropic part scales as a shape style. The co-analysis then allows style transfer to synthesize new objects. The key to co-analysis is part correspondence, where a major challenge is the handling of large style variations and diverse geometric content in the shape set. We propose style-content separation as a means to address this challenge …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Shy Shalom, Ariel Shamir, Hao Zhang, and Daniel Cohen-Or
In ACM Trans. on Graphics (Proceeding of SIGGRAPH Asia 2010), Volume 29, Number 6, Article 150 (2010)
We present cone carving, a novel space carving technique towards topologically correct surface reconstruction from an incomplete scanned point cloud. The technique utilizes the point samples not only for local surface position estimation but also to obtain global visibility information under the assumption that each acquired point is visible from a point laying outside the shape. This enables associating each point with a generalized cone, called the visibility cone, that carves a portion of the outside ambient space of the shape from the inside out.
[
![]() Paper
]
Paper
]

Yotam Livny, Feilong Yan, Matt Olson, Baoquan Chen, Hao Zhang, and Jihad El-Sana
In ACM Trans. on Graphics (Proceeding of SIGGRAPH Asia 2010), Volume 29, Number 6, Article 151 (2010)
In this paper, we perform active laser scanning of real world vegetation and present an automatic approach that robustly reconstructs skeletal structures of trees, from which full geometry can be generated. The core of our method is a series of {\it global optimizations} that fit skeletal structures to the often sparse, incomplete, and noisy point data. A significant benefit of our approach is its ability to reconstruct multiple overlapping trees simultaneously without segmentation.
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Liangliang Nan, Andrei Sharf, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen
In ACM Trans. on Graphics (Proceeding of SIGGRAPH 2010), Volume 29, Number 4, Article 93 (2010)
We introduce an interactive tool which enables a user to quickly assemble an architectural model directly over a 3D point cloud acquired from large-scale scanning of an urban scene. The user loosely defines and manipulates simple building blocks, which we call SmartBoxes, over the point samples. These boxes quickly snap to their proper locations to conform to common architectural structures. The key idea is that the building blocks are smart …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Lior Shapira, Shy Shalom, Ariel Shamir, Daniel Cohen-Or, and Hao Zhang
In International Journal of Computer Vision, Vol. 89, No. 1-2, pp. 309-326 (2010)
We address the problem of finding analogies between parts of 3D objects. By partitioning an object into meaningful parts and finding analogous parts in other objects, not necessarily of the same type, based on a contextual signature, many analysis and modeling tasks could be enhanced …
[
![]() Paper
]
Paper
]
Junjie Cao, Andrea Tagliasacchi, Matt Olson, Hao Zhang, and Zhixun Su
In Proc. of IEEE SMI, pp. 187-197 (2010)
We present an algorithm for curve skeleton extraction via Laplacian-based contraction. Our algorithm can be applied to surfaces with boundaries, polygon soups, and point clouds. We develop a contraction operation that is designed to work on generalized discrete geometry data, particularly point clouds, via local Delaunay triangulation and topological thinning …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]
Hao Zhang, Oliver van Kaick, and Ramsay Dyer
In Computer Graphics Forum, Volume 29, Number 6, pp. 1865-1894 (2010)
We provide the first comprehensive survey on spectral mesh processing. Spectral methods for mesh processing and analysis rely on eigenvalues, eigenvectors, or eigenspace projections derived from appropriately defined mesh operators to carry out desired tasks …
[
![]() Paper
]
Paper
]
Oliver van Kaick, Aaron Ward, Ghassan Hamarneh, Mark Schweitzer, and Hao Zhang
In Academic Radiology, Vol. 17, No. 8, pp. 1040-1049 (2010)
Supraspinatus muscle disorders are frequent and debilitating, resulting in pain and a limited range of shoulder motion. The gold standard for diagnosis involves an invasive surgical procedure … we present a method to classify 3D shapes of the muscle into the relevant pathology groups, based on MRIs. The method learns the Fourier coefficients that best distinguish the different classes …
[
![]() Paper
]
Paper
]
Oliver van Kaick, Hao Zhang, Ghassan Hamarneh, Daniel Cohen-Or
In Eurographics 2010 State-of-the-Art Report, TBA (2010)
We present a review of the correspondence problem targeted towards the computer graphics audience. This survey is motivated by recent developments such as advances in the correspondence of non-rigid or isometric shapes and methods that extract semantic information from the shapes …
[
![]() Paper
]
Paper
]

Qian Zheng, Andrei Sharf, Andrea Tagliasacchi, Baoquan Chen, Hao Zhang, Alla Sheffer, Daniel Cohen-Or
In Computer Graphics Forum (Proceeding of Eurographics 2010), Volume 29, Number 2, pp. 635-644 (2010)
We introduce the notion of consensus skeletons for non-rigid space-time registration of a deforming shape. Instead of basing the registration on point features, which are local and sensitive to noise, we adopt the curve skeleton of the shape as a global and descriptive feature for the task. Our method uses no template and only assumes that the skeletal structure of the captured shape remains largely consistent over time …
[
![]() Paper
]
Paper
]
Zhenglong Zhou, Ping Tan
In European Conference on Computer Vision (ECCV) (2010)
We propose a novel algorithm for uncalibrated photometric stereo. While most of previous methods rely on various assumptions on scene properties, we exploit constraints in lighting configurations. We first derive an ambiguous reconstruction by requiring lights to lie on a view centered cone. This reconstruction is upgraded to Euclidean by constraints derived from lights of equal intensity and multiple view geometry.
[
![]() Paper
]
Paper
]
Boxin Shi, Yasuyuki Matsushita, Yichen Wei, Chao Xu, Ping Tan
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2010)
We present a self-calibrating photometric stereo method. From a set of images taken from a fixed viewpoint under different and unknown lighting conditions, our method automatically determines a radiometric response function and resolves the generalized bas-relief ambiguity for estimating accurate surface normals and albedos. We show that color and intensity profiles, which are obtained from registered pixels across images, serve as effective cues for addressing these two calibration problems.
[
![]() Paper
]
Paper
]
Olson M, Zhang H.
In Computer Graphics Forum (2009)
We consider a tangent-space representation of surfaces that maps each point on a surface to the tangent plane of the surface at that point. Such representations are known to facilitate the solution of several visibility problems, in particular, those involving silhouette analysis. In this paper, we introduce a novel class of distance fields for a given surface defined by its tangent planes. At each point in space, we assign a scalar value which is a weighted sum of distances to these tangent planes. We call the resulting scalar field a ‘tangential distance field’ (TDF). When applied to triangle mesh models, the tangent planes become supporting planes of the mesh triangles. The weighting scheme used to construct a TDF for a given mesh and the way the TDF is utilized can be closely tailored to a specific application. At the same time, the TDFs are continuous, lending themselves to standard optimization techniques such as greedy local search, thus leading to efficient algorithms.
[
![]() Paper
]
Paper
]

Xu K, Zhang H, Tagliasacchi A, Liu L, Li G, Meng M, Xiong Y.
In ACM Trans. on Graphics, (Proceedings of SIGGRAPH Asia 2009) (2009)
While many 3D objects exhibit various forms of global symmetries, prominent intrinsic symmetries which exist only on parts of an object are also well recognized. Such partial symmetries are often seen as more natural compared to a global one, especially on a composite shape. We introduce algorithms to extract partial intrinsic reflectional symmetries (PIRS) of a 3D shape. Given a closed 2-manifold mesh, we develop a voting scheme to obtain an intrinsic reflectional symmetry axis (IRSA) transform, which computes a scalar field over the mesh so as to accentuate prominent IRSAs of the shape. We then extract a set of explicit IRSA curves on the shape based on a refined measure of local reflectional symmetry support along a curve. The iterative refinement procedure combines IRSA-induced region growing and region-constrained symmetry support refinement to improve accuracy and address potential issues due to rotational symmetries in the shape. We show how the extracted IRSA curves can be incorporated into a conventional mesh segmentation scheme so that the implied symmetry cues can be utilized to obtain more meaningful results. We also demonstrate the use of IRSA curves for symmetry-driven part repair.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]
Humphries T, Saad A, Celler A, Hamarneh G, Möller T, Trummer M.
In Proceedings of 2009 IEEE Nuclear Science Symposium and Medical Imaging Conference (2009)
Dynamic SPECT reconstruction using a single slow camera rotation is a highly underdetermined problem, which requires the use of regularization techniques to obtain useful results. The dSPECT algorithm (Farncombe et al. 1999) provides temporal but not spatial regularization, resulting in poor contrast and low activity levels in organs of interest, due mostly to blurring. In this paper we incorporate a user-assisted segmentation algorithm (Saad et al. 2008) into the reconstruction process to improve the results. Following an initial reconstruction using the existing dSPECT technique, a user places seeds in the image to indicate regions of interest (ROIs). A random-walk based automatic segmentation algorithm then assigns every voxel in the image to one of the ROIs, based on its proximity to the seeds as well as the similarity between time activity curves (TACs). The user is then able to visualize the segmentation and improve it if necessary. Average TACs are extracted from each ROI and assigned to every voxel in the ROI, giving an image with a spatially uniform TAC in each ROI. This image is then used as initial input to a second run of dSPECT, in order to adjust the dynamic image to better fit the projection data. We test this approach with a digital phantom simulating the kinetics of Tc99m-DTPA in the renal system, including healthy and unhealthy behaviour. Summed TACs for each kidney and the bladder were calculated for the spatially regularized and non-regularized reconstructions, and compared to the true values. The TACs for the two kidneys were noticeably improved in every case, while TACs for the smaller bladder region were unchanged. Furthermore, in two cases where the segmentation was intentionally done incorrectly, the spatially regularized reconstructions were still as good as the non-regularized ones. In general, the segmentation-based regularization improves TAC quality within ROIs, as well as image contrast.
[
![]() Paper
]
Paper
]
Tagliasacchi A, Zhang H, Cohen-Or D.
In ACM Transactions on Graphics, (Proceedings SIGGRAPH 2009) (2009)
We present an algorithm for curve skeleton extraction from imperfect point clouds where large portions of the data may be missing. Our construction is primarily based on a novel notion of generalized rotational symmetry axis (ROSA) of an oriented point set. Specifically, given a subset S of oriented points, we introduce a variational definition for an oriented point that is most rotationally symmetric with respect to S. Our formulation effectively utilizes normal information to compensate for the missing data and leads to robust curve skeleton computation over regions of a shape that are generally cylindrical. We present an iterative algorithm via planar cuts to compute the ROSA of a point cloud. This is complemented by special handling of non-cylindrical joint regions to obtain a centered, topologically clean, and complete 1D skeleton. We demonstrate that quality curve skeletons can be extracted from a variety of shapes captured by incomplete point clouds. Finally, we show how our algorithm assists in shape completion under these challenges by developing a skeleton-driven point cloud completion scheme.
[
![]() Paper
]
Paper
]
Li X, Jia T, Zhang H.
In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2009)
We present a face recognition method based on sparse representation for recognizing 3D face meshes under expressions using low-level geometric features. First, to enable the application of the sparse representation framework, we develop a uniform remeshing scheme to establish a consistent sampling pattern across 3D faces.
[
![]() Paper
]
Paper
]
Vuçini E, Möller T, Gröller E.
In Computer Graphics Forum (Proceedings of Eurographics/IEEE-VGTC Symposium on Visualization 2009 (EuroVis 2009)) (2009)
We present a novel framework for the visualization and reconstruction from non-uniform point sets. We adopt a variational method for the reconstruction of 3D non-uniform data to a uniform grid of chosen resolution. We will extend this reconstruction to an efficient multi-resolution uniform representation of the underlying data. Our multi-resolution representation includes a traditional bottom-up approach and a novel top-down hierarchy for adaptive hierarchical reconstruction. Using a hybrid regularization functional we can improve the reconstruction results. Finally, we discuss further application scenarios and show rendering results to emphasize the effectiveness and quality of our proposed framework. By means of qualitative results and error comparisons we demonstrate superiority of our method compared to competing methods.
[
![]() Paper
]
Paper
]
Chuang J, Weiskopf D, Möller T.
In EEE Transactions on Visualization and Computer Graphics (Proceedings Visualization / Information Visualization 2009) (2009)
We propose a new perception-guided compositing operator for color blending. The operator maintains the same rules for achromatic compositing as standard operators (such as the over operator), but it modifies the computation of the chromatic channels. Chromatic compositing aims at preserving the hue of the input colors; color continuity is achieved by reducing the saturation of colors that are to change their hue value. The main benefit of hue preservation is that color can be used for proper visual labeling, even under the constraint of transparency rendering or image overlays. Therefore, the visualization of nominal data is improved. Hue-preserving blending can be used in any existing compositing algorithm, and it is particularly useful for volume rendering. The usefulness of hue-preserving blending and its visual characteristics are shown for several examples of volume visualization.
[ ]
Finkbeiner B, Alim UR, Van De Ville D, Möller T.
In Computer Graphics Forum (Proceedings of Eurographics/IEEE-VGTC Symposium on Visualization (EuroVis 2009)) (2009)
Within the context of emission tomography, we study volumetric reconstruction methods based on the Expectation Maximization (EM) algorithm. We show, for the first time, the equivalence of the standard implementation of the EM-based reconstruction with an implementation based on hardware-accelerated volume rendering for nearest-neighbor (NN) interpolation. This equivalence suggests that higher-order kernels should be used with caution and do not necessarily lead to better performance. We also show that the EM algorithm can easily be adapted for different lattices, the body-centered cubic (BCC) one in particular. For validation purposes, we use the 3D version of the Shepp-Logan synthetic phantom, for which we derive closed-form analytical expressions of the projection data.
[
![]() Paper
]
Paper
]
Dyer R, Zhang H, Möller T.
In Proceedings of SIAM/ACM Conference on Geometric and Physical Modeling (2009)
We undertake a study of the local properties of 2-Gabriel meshes: manifold triangle meshes each of whose faces has an open Euclidean diametric ball that contains no mesh vertices. We show that, under mild constraints on the dihedral angles, such meshes are Delaunay meshes: the open geodesic circumdisk of each face contains no mesh vertex. The analysis is done by means of the Delaunay edge flipping algorithm and it reveals the details of the distinction between these two mesh structures. In particular we observe that the obstructions which prohibit the existence of Gabriel meshes as homeomorphic representatives of smooth surfaces do not hinder the construction of Delaunay meshes.
[
![]() Paper
]
Paper
]

Xu K, Cohne-Or D, Ju T, Liu L, Zhang H, Zhou S, Xiong Y.
In ACM Transactions on Graphics, (Proceedings SIGGRAPH Asia 2009) (2009)
The essence of a 3D shape can often be well captured by its salient feature curves. In this paper, we explore the use of salient curves in synthesizing intuitive, shape-revealing textures on surfaces. Our texture synthesis is guided by two principles: matching the direction of the texture patterns to those of the salient curves, and aligning the prominent feature lines in the texture to the salient curves exactly. We have observed that textures synthesized by these principles not only fit naturally to the surface geometry, but also visually reveal, even reinforce, the shape’s essential characteristics. We call these feature-aligned shape texturing. Our technique is fully automatic, and introduces two novel technical components in vector-field-guided texture synthesis: an algorithm that orients the salient curves on a surface for constrained vector field generation, and a feature-to-feature texture optimization.
[
![]() Paper
]
Paper
]
Huang H, Li D, Zhang H, Ascher U, Cohen-Or D.
In ACM Transactions on Graphics, (Proceedings SIGGRAPH Asia 2009) (2009)
We consolidate an unorganized point cloud with noise, outliers, non-uniformities, and in particular interference between close-by surface sheets as a preprocess to surface generation, focusing on reliable normal estimation. Our algorithm includes two new developments. First, a weighted locally optimal projection operator produces a set of denoised, outlier-free and evenly distributed particles over the original dense point cloud, so as to improve the reliability of local PCA for initial estimate of normals. Next, an iterative framework for robust normal estimation is introduced, where a priority-driven normal propagation scheme based on a new priority measure and an orientation-aware PCA work complementarily and iteratively to consolidate particle normals. The priority setting is reinforced with front stopping at thin surface features and normal flipping to enable robust handling of the close-by surface sheet problem. We demonstrate how a point cloud that is well-consolidated by our method steers conventional surface generation schemes towards a proper interpretation of the input data.
[
![]() Paper
]
Paper
]
Bergner S., Van De Ville D., Blu T., Möller T..
In Proc. of SAMPTA 2009 (2009)
We provide a method for constructing regular sampling lattices in arbitrary dimensions together with an integer dilation matrix. Subsampling using this dilation matrix leads to a similarity-transformed version of the lattice with a chosen density reduction. These lattices are interesting candidates for multidimensional wavelet constructions with a limited number of subbands.
[
![]() Paper
]
Paper
]
Liu R, Zhang H, Shamir A, Cohen-Or D.
In Computer Graphics Forum (Special Issue of Eurographics 2009) (2009)
The main contribution of our work is to bring together these two fundamental concepts: shape parts and surface metric. Specifically, we develop a surface metric that is part-aware. To encode part information at a point on a shape, we model its volumetric context – called the volumetric shape image (VSI) – inside the shape’s enclosed volume, to capture relevant visibility information. We then define the part-aware metric by combining an appropriate VSI distance with geodesic distance and normal variation. We show how the volumetric view on part separation addresses certain limitations of the surface view, which relies on concavity measures over a surface as implied by the well-known minima rule. We demonstrate how the new metric can be effectively utilized in various applications including mesh segmentation, shape registration, part-aware sampling and shape retrieval.
[
![]() Paper
]
Paper
]
Olson M, Zhang H.
In Computer Graphics Forum (2009)
We consider a tangent-space representation of surfaces that maps each point on a surface to the tangent plane of the surface at that point. Such representations are known to facilitate the solution of several visibility problems, in particular, those involving silhouette analysis. In this paper, we introduce a novel class of distance fields for a given surface defined by its tangent planes. At each point in space, we assign a scalar value which is a weighted sum of distances to these tangent planes. We call the resulting scalar field a ‘tangential distance field’ (TDF). When applied to triangle mesh models, the tangent planes become supporting planes of the mesh triangles. The weighting scheme used to construct a TDF for a given mesh and the way the TDF is utilized can be closely tailored to a specific application. At the same time, the TDFs are continuous, lending themselves to standard optimization techniques such as greedy local search, thus leading to efficient algorithms. In this paper, we use four applications to illustrate the benefit of using TDFs: multi-origin silhouette extraction in Hough space, silhouette-based view point selection, camera path planning and light source placement.
[
![]() Paper
]
Paper
]

Alim UR, Entezari A, Möller T.
In IEEE Transactions on Visualization and Computer Graphics (TVCG) (2009)
We extend the single relaxation time lattice-Boltzmann method (LBM) to the 3D body-centered cubic (BCC) lattice. We show that the D3bQ15 lattice defined by a 15 neighborhood connectivity of the BCC lattice is not only capable of more accurately discretizing the velocity space of the continuous Boltzmann equation as compared to the D3Q15 Cartesian lattice, it also achieves a comparable spatial discretization with 30 percent less samples. We validate the accuracy of our proposed lattice by investigating its performance on the 3D lid-driven cavity flow problem and show that the D3bQ15 lattice offers significant cost savings while maintaining a comparable accuracy. We demonstrate the efficiency of our method and the impact on graphics and visualization techniques via the application of line-integral convolution on 2D slices as well as the extraction of streamlines of the 3D flow. We further study the benefits of our proposed lattice by applying it to the problem of simulating smoke and show that the D3bQ15 lattice yields more detail and turbulence at a reduced computational cost.
[
![]() Paper
]
Paper
]

Bergner S., Drew M.S, Möller T.
In ACM Trans. Graph (2009)
Full spectra allow the generation of a physically correct rendering of a scene under different lighting conditions. In this article we devise a tool to augment a palette of given lights and material reflectances with constructed spectra, yielding specified colors or spectral properties such as metamerism or objective color constancy. We utilize this to emphasize or hide parts of a scene by matching or differentiating colors under different illuminations. These color criteria are expressed as a quadratic programming problem, which may be solved with positivity constraints. Further, we characterize full spectra of lights, surfaces, and transmissive materials in an efficient linear subspace model by forming eigenvectors of sets of spectra and transform them to an intermediate space in which spectral interactions reduce to simple component-wise multiplications during rendering. The proposed method enhances the user’s freedom in designing photo-realistic scenes and helps in creating expressive visualizations. A key application of our technique is to use specific spectral lighting to scale the visual complexity of a scene by controlling visibility of texture details in surface graphics or material details in volume rendering.
[
![]() Paper
]
Paper
]
Ramsay Dyer, Hao Zhang, and Torsten Moeller
In Computer Graphics Forum (Special Issue of SGP), Volume 27, Number 5, pp. 1431-1439 (2008)
We develop adaptive sampling criteria which guarantee a topologically faithful mesh and demonstrate an improvement and simplification over earlier results, albeit restricted to 2D surfaces. These sampling criteria are based on the strong convexity radius and the injectivity radius …
[
![]() Paper
]
Paper
]

Hao Zhang, Alla Sheffer, Daniel Cohen-Or, Qingnan Zhou, Oliver van Kaick, and Andrea Tagliasacchi
In Computer Graphics Forum (Special Issue of SGP), Volume 27, Number 5, pp. 1393-1402 (2008)
We present an automatic feature correspondence algorithm capable of handling large, non-rigid shape variations, as well as partial matching … The search is deformation-driven, prioritized by a self-distortion energy measured on meshes deformed according to a given correspondence …
[
![]() Paper
|
Paper
|
![]() Project Page
]
Project Page
]

Rong Liu, Hao Zhang, and James Busby
In Proc. of Graphics Interface 2008, pp. 203-210 (2008)
We look at a particular instance of the convex decomposition problem which arises from real-world game development. Given a collection of polyhedral surfaces (possibly with boundaries, holes, and complex interior structures) that model the scene geometry in a game environment, we wish to find a small set of convex hulls …
[
![]() Paper
]
Paper
]

Ping Tan, Tian Fang, Jianxiong Xiao, Peng Zhao, Long Quan
In ACM Transaction on Graphics(TOG) and Proc. of SIGGRAPH Asia (2008)
In this paper, we introduce a simple sketching method to generate a realistic 3D tree model from a single image. The user draws at least two strokes in the tree image: the first crown stroke around the tree crown to mark up the leaf region, the second branch stroke from the tree root to mark up the main trunk, and possibly few other branch strokes for refinement. The method automatically generates a 3D tree model including branches and leaves. Branches are synthesized by a growth engine from a small library of elementary subtrees that are pre-defined or built on the fly from the recovered visible branches.
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Jianxiong Xiao, Tian Fang, Ping Tan, Peng Zhao, Eyal Ofek, Long Quan
In ACM Transaction on Graphics(TOG) and Proc. of SIGGRAPH Asia (2008)
We propose in this paper a semi-automatic image-based approach to fac¸ade modeling that uses images captured along streets and relies on structure from motion to recover camera positions and point clouds automatically as the initial stage for modeling. We start by considering a building fac¸ade as a flat rectangular plane or a developable surface with an associated texture image composited from the multiple visible images
[
![]() Paper
|
Paper
|
![]() Project Page
|
Project Page
|
![]() Video
]
Video
]

Ping Tan, Stephen Lin, Long Quan
In IEEE Transaction on Pattern Analysis and Machine Intelligence (TPAMI) (2008)
In this paper, we propose a method to recover subpixel surface geometry by studying the relationship between the subpixel geometry and the reflectance properties of a surface. We first describe a generalized physically-based reflectance model that relates the distribution of surface normals inside each pixel area to its reflectance function. The distribution of surface normals can be computed from the reflectance functions recorded in photometric stereo images. A convexity measure of subpixel geometry structure is also recovered at each pixel, through an analysis of brightness attenuation due to shadowing. Then, we use the recovered distribution of surface normals and the surface convexity to infer subpixel geometric structures on a surface of homogeneous material by spatially arranging the normals among pixels at a higher resolution than that of the input image
[
![]() Paper
]
Paper
]

Ping Tan, Stephen Lin, Long Quan, Baining Guo, Heung-Yeung Shum
In IEEE Transaction on Visualization and Computer Graphics (TVCG) (2008)
In this work, we propose to represent this resolution-dependent reflectance as a mixture of multiple conventional reflectance models, and present a framework for efficiently rendering the reflectance effects of such mixture models over different resolutions. To rapidly determine reflectance at runtime with respect to resolution, we record the mixture model parameters at multiple resolution levels in mipmaps, and propose a technique to minimize aliasing in the filtering of these mipmaps. This framework can be applied to several widely used parametric reflectance models and can be implemented in graphics hardware for real-time processing, using a presented hardware-accelerated technique for non-linear filtering of mixture model parameters.
[
![]() Paper
]
Paper
]

Li Shen, Ping Tan, Stephen Lin
In IEEE Conference on Computer Vision and Patten Recognition (CVPR) (2008)
We present a method for decomposing an image into its intrinsic reflectance and shading components. Different from previous work, our method examines texture information to obtain constraints on reflectance among pixels that may be distant from one another in the image. We observe that distinct points with the same intensity-normalized texture configuration generally have the same reflectance value. The separation of shading and reflectance components should thus be performed in a manner that guarantees these non-local constraints
[
![]() Paper
]
Paper
]

Crider M, Bergner S, Smyth TN, Möller T, Tory MK, Kirkpatrick E., Weiskopf D.
In Graphics Interface 2007 (2007)
We use a haptically enhanced mixing board with a video projector as an interface to various data visualization tasks. We report results of an expert review with four participants, qualitatively evaluating the board for three different applications: dynamic queries (abstract task), parallel coordinates interface (multi-dimensional combinatorial search), and ExoVis (3D spatial navigation). Our investigation sought to determine the strengths of this physical input given its capability to facilitate bimanual interaction, constraint maintenance, tight coupling of input and output, and other features.
[
![]() Paper
]
Paper
]
Jain V, Zhang H, van Kaick O.
In International Journal on Shape Modeling (2007)
We present an algorithm for finding a meaningful vertex-to-vertex correspondence between two triangle meshes, which is designed to handle general non-rigid transformations. Our algorithm operates on embeddings of the two shapes in the spectral domain so as to normalize them with respect to uniform scaling and rigid-body transformation. Invariance to shape bending is achieved by relying on approximate geodesic point proximities on a mesh to capture its shape. To deal with moderate stretching, we first raise the issue of “eigenmode switching” and discuss heuristics to bring the eigenmodes to alignment. For additional non-rigid discrepancies in the spectral embeddings, we propose to use non-rigid alignment via thin-plate splines. This is combined with a refinement step based on geodesic proximities to improve dense correspondence. We show empirically that our algorithm outperforms previous spectral methods, as well as schemes that compute correspondence in the spatial domain via non-rigid iterative closest points or the use of local shape descriptors, e.g., 3D shape context. Finally, to speed up our algorithm, we examine the effect of using subsampling and Nystrom method.
[ ]

Li X, Zhang H.
In Shape Modeling International (2007)
We investigate the use of multiple intrinsic geometric attributes, including angles, geodesic distances, and curvatures, for 3D face recognition, where each face is represented by a triangle mesh, preprocessed to possess a uni- form connectivity. As invariance to facial expressions holds the key to improving recognition performance, we propose to train for the component-wise weights to be applied to each individual attribute, as well as the weights used to combine the attributes, in order to adapt to expression variations. Using the eigenface approach based on the training results and a nearest neighbor classifier, we report recognition results on the expression-rich GavabDB face database and the well-known Notre Dame FRGC 3D database. We also perform a cross validation between the two databases.
[
![]() Paper
]
Paper
]
Jennings C.G, Kirkpatrick A.E.
In In Proceedings of Graphics Interface 2007 (2007)
We present a design space explorer for the space of experimental designs. For many design problems, design decisions are determined by the consequences of the design rather than its elemental parts. To support this need, the explorer is constructed to make the designer aware of design-level options, provide a structured context for design, and provide feedback on the consequences of design decisions. We argue that this approach encourages the designer to consider a wider variety of designs, which will lead to more effective designs overall. In a qualitative study, experiment designers using the explorer were found to consider a wider variety of designs and more designs overall than they reported considering in their normal practice.
[
![]() Paper
]
Paper
]

Jain V, Zhang H.
In Computer Aided Design (2007)
We present an approach for robust shape retrieval from databases containing articulated 3D models. Each shape is represented by the eigenvectors of an appropriately defined affinity matrix, forming a spectral embedding which achieves normalization against rigid-body transformations, uniform scaling, and shape articulation (i.e., bending).
[
![]() Paper
]
Paper
]
M. Atkins S, Kirkpatrick AE, Knight A.
In In Proceedings of the SPIEMedical Imaging 2007. (2007)
Three interaction techniques were evaluated for scrolling stack mode displays of volumetric data. Two used a scroll-wheel mouse: one used only the wheel, while another used a “click and drag” technique for fast scrolling, leaving the wheel for fine adjustments. The third technique used a Shuttle Xpress jog wheel. In a within-subjects design, nine radiologists searched stacked images for simulated hyper-intense regions on brain, knee, and thigh MR studies. Dependent measures were speed, accuracy, navigation path, and user preference.
[
![]() Paper
]
Paper
]

Liu R, Zhang H.
In Computer Graphics Forum (Special Issue of Eurographics 2007) (2007)
We propose a mesh segmentation algorithm via recursive bisection where at each step, a sub-mesh embedded in 3D is first spectrally projected into the plane and then a contour is extracted from the planar embedding. We rely on two operators to compute the projection: the well-known graph Laplacian and a geometric operator designed to emphasize concavity.
[
![]() Paper
]
Paper
]
Dyer R, Zhang H, Möller T..
In Proc. of Eurographics Symposium on Geometry Processing (2007)
We present algorithms to produce Delaunay meshes from arbitrary triangle meshes by edge flipping and geometrypreserving refinement and prove their correctness. In particular we show that edge flipping serves to reduce mesh surface area, and that a poorly sampled input mesh may yield unflippable edges necessitating refinement to ensure a Delaunay mesh output. Multiresolution Delaunay meshes can be obtained via constrained mesh decimation. We further examine the usefulness of trading off the geometry-preserving feature of our algorithm with the ability to create fewer triangles. We demonstrate the performance of our algorithms through several experiments.
[
![]() Paper
]
Paper
]

van Kaick O, Hamarneh G, Zhang H, Wighton P.
In Proc. Pacific Graphics (2007)
We formulate contour correspondence as a Quadratic Assignment Problem (QAP), incorporating proximity information. By maintaining the neighborhood relation between points this way, we show that better matching results are obtained in practice. We propose the first Ant Colony Optimization (ACO) algorithm specifically aimed at solving the QAP-based shape correspondence problem.
[
![]() Paper
]
Paper
]
Jain V, Zhang H, van Kaick O.
In International Journal on Shape Modeling (2007)
We present an algorithm for finding a meaningful vertex-to-vertex correspondence between two triangle meshes, which is designed to handle general non-rigid transformations. Our algorithm operates on embeddings of the two shapes in the spectral domain so as to normalize them with respect to uniform scaling and rigid-body transformation. Invari-ance to shape bending is achieved by relying on approximate geodesic point proximities on a mesh to capture its shape.
[
![]() Paper
]
Paper
]

Dyer R, Zhang H, Möller T..
In ACM Symposium on Solid and Physical Modeling (2007)
We define a Delaunay mesh to be a manifold triangle mesh whose edges form an intrinsic Delaunay triangulation or iDT of its vertices, where the triangulated domain is the piecewise flat mesh surface. We show that meshes constructed from a smooth surface by taking an iDT or a restricted Delaunay triangulation, do not in general yield a Delaunay mesh.
[
![]() Paper
]
Paper
]
John Li and Hao Zhang
In in Proc. of Symposium on Geometry Processing (SGP) 2006 (short paper), pp.235-238 (2006)
We propose an algorithm for guaranteed nonobtuse remeshing and nonobtuse mesh decimation. Our strategy for the remeshing problem is to first convert an input mesh, using a modified Marching Cubes algorithm, into a rough approximate mesh that is guaranteed to be nonobtuse. We then apply iterative “deform-to-fit” …
[
![]() Paper
]
Paper
]

Matt Olson and Hao Zhang
In Computer Graphics Forum (Special Issue on Eurographics 2006), Volume 25, Number 3, pp. 273-282 (2006)
We present an efficient silhouette extractor for triangle meshes under perspective projection in the Hough space. The more favorable point distribution in Hough space allows us to obtain significant performance gains over the traditional dual-space based techniques …
[
![]() Paper
]
Paper
]
Varun Jain and Hao Zhang
In in Proceeding of Geometric Modeling and Processing 2006, pp. 295-308 (2006)
We present a spectral approach for robust shape retrieval from databases containing articulated 3D shapes. We show absolute improvement in retrieval performance when conventional shape descriptors are used in the spectral domain on the McGill database of articulated 3D shapes. We also propose a simple eigenvalue-based descriptor …
[
![]() Paper
]
Paper
]
Rong Liu, Hao Zhang, and Oliver van Kaick
In in Proceeding of Geometric Modeling and Processing 2006 (poster paper), pp. 632-638 (2006)
In this paper, we treat optimal mesh layout generation as a problem of preserving graph distances and propose to use the subdominant eigenvector of a kernel (affinity) matrix for sequencing …
[
![]() Paper
]
Paper
]
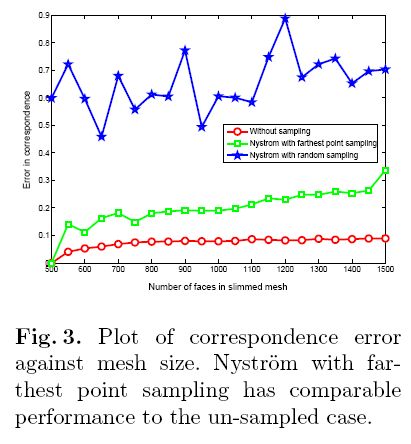
Rong Liu, Varun Jain, and Hao Zhang
In in Proceeding of Computer Graphics International 2006, Lecture Notes in Computer Science 4035, H.-P. Seidel, T. Nishita, and Q. Peng, Eds., pp. 172-184 (2006)
We apply Nystrom method, a sub-sampling and reconstruction technique, to speed up spectral mesh processing. We first relate this method to Kernel Principal Component Analysis (KPCA). This enables us to derive a novel measure in the form of a matrix trace, based soly on sampled data, to quantify the quality of Nystrom approximation …
[
![]() Paper
]
Paper
]

Varun Jain and Hao Zhang
In in Proceeding of International Conference on Shape Modeling and Applications (SMI) 2006, pp. 118-129 (2006)
We present an algorithm for finding a meaningful correspondence between two 3D shapes given as triangle meshes. Our algorithm operates on embeddings of the two shapes in the spectral domain so as to normalize them with respect to uniform scaling, rigid-body transformation and shape bending …
[
![]() Paper
]
Paper
]

Andrew Clements and Hao Zhang
In in Proceeding of International Conference on Shape Modeling and Applications (SMI) 2006, pp. 26-37 (2006)
We present a novel approach for discretely optimizing contours on the surface of a triangle mesh. This is achieved through the use of a minimum ratio cycle (MRC) algorithm, where we compute a contour having the minimal ratio between a novel contour energy term and the length of the contour …
[
![]() Paper
]
Paper
]

Xiaoxing Li, Greg Mori, and Hao Zhang
In in Proceeding of Canadian Conference on Computer and Robot Vision (CRV) 2006, pp. 77-83 (2006)
Facial expression, which changes face geometry, usually has an adverse effect on the performance of a face recognition system. On the other hand, face geometry is a useful cue for recognition. Taking these into account, we utilize the idea of separating geometry and texture information in a face image …
[
![]() Paper
]
Paper
]

Long Quan, Ping Tan, Gang Zeng, Lu Yuan, Jingdong Wang, Sing Bing Kang
In ACM Transaction on Graphics(TOG) and Proc. of SIGGRAPH (2006)
In this paper, we propose a semi-automatic technique for modeling plants directly from images. Our image-based approach has the distinct advantage that the resulting model inherits the realistic shape and complexity of a real plant. We designed our modeling system to be interactive, automating the process of shape recovery while relying on the user to provide simple hints on segmentation. Segmentation is performed in both image and 3D spaces, allowing the user to easily visualize its effect immediately
[
![]() Paper
]
Paper
]

Ping Tan, Stephen Lin, Long Quan
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2006)
We present a method for separating highlight reflections on textured surfaces. In contrast to previous techniques that use diffuse color information from outside the highlight area to constrain the solution, the proposed method further capitalizes on the spatial distributions of colors to resolve ambiguities in separation that often arise in real images. For highlight pixels in which a clear-cut separation cannot be determined from color space analysis, we evaluate possible separation solutions based on their consistency with diffuse texture characteristics outside the highlight
[
![]() Paper
]
Paper
]

Ping Tan, Stephen Lin, Long Quan
In European Conference on Computer Vision(ECCV) (2006)
In this work, we propose a technique for resolution-enhanced photometric stereo, in which surface geometry is computed at a resolution higher than that of the input images. To achieve this goal, our method first utilizes a generalized reflectance model to recover the distribution of surface normals inside each pixel. This normal distribution is then used to infer sub-pixel structures on a surface of uniform material by spatially arranging the normals among pixels at a higher resolution according to a minimum description length criterion on 3D textons over the surface
[
![]() Paper
]
Paper
]
Bergner S, Möller T, Tory M, Drew MS.
In IEEE Trans. on Vis. and Comp. Graphics (2005)
To make a spectral representation of color practicable for volume rendering, a new low-dimensional subspace method is used to act as the carrier of spectral information. With that model, spectral light material interaction can be integrated into existing volume rendering methods at almost no penalty. In addition, slow rendering methods can profit from the new technique of postillumination-generating spectral images in real-time for arbitrary light spectra under a fixed viewpoint. Thus, the capability of spectral rendering to create distinct impressions of a scene under different lighting conditions is established as a method of real-time interaction.
[
![]() Paper
]
Paper
]

Jain V, Zhang H.
In Proc. of Pacific Graphics (2005)
We present a robust shape descriptor for points along a 2D contour, based on the curvature distribution collected over bins arranged geodesically along the contour. Convolution, binning and hysteresis thresholding of curvatures are applied to render the descriptor more robust against noise and non-rigid shape deformation. Once the shape descriptor is computed for every point or feature vertex of the two shapes to be matched, a one-to-one correspondence can be quickly established through best matching of the descriptors, aided by a proximity heuristic.
[
![]() Paper
]
Paper
]

Bergner S, Dagenais E, Möller T, Celler A.
In IEEE Nuclear Science Symposium and Medical Imaging Conference Record (2005)
In this paper we cast the problem of tomography in the realm of computer graphics. By using PBRT (physically based rendering toolkit) we create a scripting environment that simplifies the programming of tomography algorithms such as Maximum-Likelihood Expectation Maximization (ML-EM) or Simultaneous Algebraic Reconstruction Technique (SART, a deviant of ART).
[
![]() Paper
]
Paper
]
Vollrath JE, Weiskopf D, Ertl T.
In In Proc. Vision, Modeling, and Visualization (2005)
We use volume graphics for realistic image synthesis taking into account aspects of visual perception by means of real-time high dynamic range tone mapping. We propose a software architecture that embeds the volume rendering pipeline by using object-oriented design patterns, layers, and the concept of a shared application state.
[
![]() Paper
]
Paper
]
Weiskopf D, al et.
In (2005)
We propose a hybrid particle and texture based approach for the visualization of time-dependent vector fields. The underlying space-time framework builds a dense vector field representation in a two-step process: 1) particle-based forward integration of trajectories in spacetime for temporal coherence, and 2) texture-based convolution along another set of paths through the spacetime for spatially correlated patterns.
[
![]() Paper
]
Paper
]
Bergner S, Drew MS.
In Proc. of IEEE Int. Conf. on Img. Proc (2005)
We investigate the implications of a unified spatiotemporal-chromatic basis for compression and reconstruction of image sequences. Different adaptive methods (PCA and ICA) are applied to generate basis functions. While typically such bases with spatial and temporal extent are investigated in terms of their correspondence to human visual perception, here we are interested in their applicability to multimedia encoding. The performance of the extracted spatiotemporal-chromatic patch bases is evaluated in terms of quality of reconstruction with respect to their potential for data compression. The results discussed here are intended to provide another path towards perceptually-based encoding of visual data by examining the interplay of chromatic features with spatiotemporal ones in data reduction.
[
![]() Paper
]
Paper
]
Weiskopf D, Borchers M, Ertl T, Falk M, Fechtig O, Frank R, Grave F, King A, Kraus U, Muller T et al..
In Visualization Conference, IEEE (2005)
In this application paper, we report on over fifteen years of experience with relativistic and astrophysical visualization, which has been culminating in a substantial engagement for visualization in the Einstein Year 2005 - the 100/sup th/ anniversary of Einstein’s publications on special relativity, the photoelectric effect, and Brownian motion. This paper focuses on explanatory and illustrative visualizations used to communicate aspects of the difficult theories of special and general relativity, their geometric structure, and of the related fields of cosmology and astrophysics. We discuss visualization strategies, motivated by physics education and didactics of mathematics, and describe what kind of visualization methods have proven to be useful for different types of media, such as still images in popular-science magazines, film contributions to TV shows, oral presentations, or interactive museum installations.
[
![]() Paper
]
Paper
]
Daniel RBotchen, Ertl T.
In In Proceedings of IEEE Visualization 2005 (2005)
We present two novel texture-based techniques to visualize uncertainty in time-dependent 2D flow fields. Both methods use semi-Lagrangian texture advection to show flow direction by streaklines and convey uncertainty by blurring these streaklines. The first approach applies a cross advection perpendicular to the flow direction. The second method employs isotropic diffusion that can be implemented by Gaussian filtering. Both methods are derived from a generic filtering process that is incorporated into the traditional texture advection pipeline. Our visualization methods allow for a continuous change of the density of flow representation by adapting the density of particle injection. All methods can be mapped to efficient GPU implementations. Therefore, the user can interactively control all important characteristics of the system like particle density, error influence, or dye injection to create meaningful illustrations of the underlying uncertainty. Even though there are many sources of uncertainties, we focus on uncertainty that occurs during data acquisition. We demonstrate the usefulness of our methods for the example of real-world fluid flow data measured with the particle image velocimetry (PIV) technique. Furthermore, we compare these techniques with an adapted multi-frequency noise approach.
[
![]() Paper
]
Paper
]